Легко подсчитать, что несжатое полноцветное изображение, размером 2000*1000 пикселов будет иметь размер около 6 мегабайт. Если говорить об изображениях, получаемых с профессиональных камер или сканеров высокого разрешения, то их размер может быть ещё больше. Не смотря на быстрый рост ёмкости устройств хранения, по-прежнему весьма актуальными остаются различные алгоритмы сжатия изображений.
Все существующие алгоритмы можно разделить на два больших класса:
Универсальные форматы веб-изображений
Они могут иметь до 16 миллионов цветов и часто используются, потому что они меньшего размера и хорошего качества. Они используются при поиске превосходного или прозрачного качества. В качестве старого формата поддерживается большинство браузеров и приложений.
На сайте могут быть все эти 3 формата, в зависимости от их использования. Имейте в виду, что нет никакого рецепта для форматирования изображений, вы можете экспериментировать с различными форматами и видеть качество и размер каждого формата для одного и того же изображения.
- Алгоритмы сжатия без потерь;
- Алгоритмы сжатия с потерями.
Алгоритмы сжатия без потерь
Алгоритм RLE
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.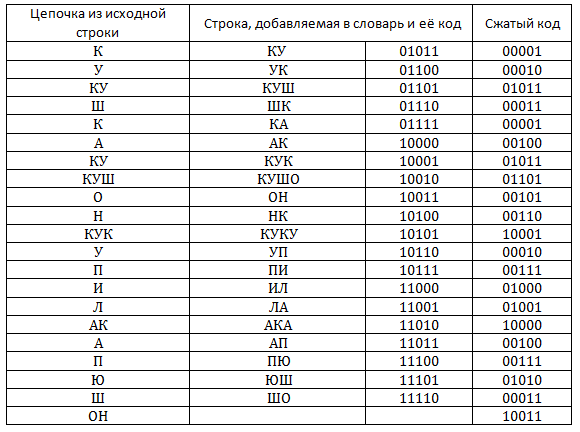
Изменение размера изображений перед загрузкой на сайт
Вот почему важно знать, как быстро и легко изменять размер изображения. Каковы шаги для изменения размера изображения с помощью этого инструмента. Шаг 5: в верхней части изображения будет больше вариантов: для профиля, для мобильных устройств, для электронной почты, для сайта. Размер по умолчанию - 800 пикселей на самой большой стороне.
Шаг 7: Открывает экран, на котором вы можете сохранить новое изображение. Изображение будет переименовано в приложение, добавив отредактированное слово в конце его имени. Если вы хотите, вы можете переименовать изображение и сохранить его на своем компьютере. Также на этом экране вы увидите размер изображения на диске.
В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c - это один символ, а S - строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Посмотрим, что еще нужно сделать для полной оптимизации. Изображения могут иметь миллионы цветных пикселей, тем больше оттенки могут различаться, изображение будет иметь больше информации, это будет очень ясно, но займет больше места на жестком диске. Таким образом, алгоритм сжатия состоит в перетасовке цветов, похожих на оттенок, которые человеческий глаз вообще не замечает. Таким образом, изображение будет иметь меньший размер диска и меньшее количество цветов.
Заключение для оптимизации изображения
После того, как вы подождите несколько секунд для сжатия, вы сможете загрузить новую версию изображения. Оптимизация изображения принесет вам пользу: менее загруженный сервер, быстрая страница на рабочем столе и мобильном телефоне, посетители, оставшиеся на странице. Чтобы изменить размер, сжать и переформатировать изображения из огня, вы можете использовать другой онлайн-инструмент, который вы найдете на этой странице.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.Алгоритм Хаффмана
Алгоритм Хаффмана позволяет строить префиксные коды. Можно рассматривать префиксные коды как пути на двоичном дереве: прохождение от узла к его левому сыну соответствует 0 в коде, а к правому сыну – 1. Если мы пометим листья дерева кодируемыми символами, то получим представление префиксного кода в виде двоичного дерева.Опишем алгоритм построения дерева Хаффмана и получения кодов Хаффмана.
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой - бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал ,"es":["6mXZvupymQA"],"pt":["UGdJom2ju4s","ajncQV0z3qY","UGdJom2ju4s","DOWOVOmgTLk","akl2DUlj9cw"],"fr":["iWImoHl0t9k"],"pl":["cWN28dMK0T0","XtT7ZEnVrbY"],"la":["Of6EBLVYKwA"],"el":}