Современные жесткие диски довольно “умные” устройства и, кроме основных присущих им как устройствам хранения и обработки данных свойств, поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (S elf-M onitoring A nalysis a nd R eporting T echnology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков (HDD). В последующие годы стандарты S.M.A.R.T дорабатывались в соответствии с изменениями технологий и оборудования (SMART II и SMART III) и продолжают совершенствоваться в настоящее время.
Жесткий диск, начиная с момента его изготовления, постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках - атрибутах (Attribute), сохраняющихся в постоянном запоминающем устройстве, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя - служебной зоне . Данные атрибутов могут быть считаны, в соответствии со спецификацией ATA (AT A ttachment) по командам поддержки SMART (SMART READ DATA и еще более десятка команд), которые передаются в накопитель специальным программным обеспечением, как например, утилитами от производителей оборудования или универсальными программами тестирования и мониторинга состояния HDD (udisks, smartctl, GSmartControl, gnome-disks и т.п.). Современные стандарты ATA включают в себя поддержку протокола SCT (SMART Command Transport), обеспечивающего считывание журналов статистики устройства. Журнал статистики устройства - это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG.
Атрибут представляет собой характеристику определенного состояния жесткого диска, которая изменяется в процессе эксплуатации, принимая числовое значение от максимального, установленного в момент изготовления данного устройства, до минимального, при достижении которого, работоспособность накопителя не гарантируется. Все атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется жесткими дисками разных моделей. Некоторые из них могут использоваться только конкретным производителем оборудования, и поддерживаться отдельными моделями накопителей. Так, например, атрибут с идентификатором 7 , характеризующий количество ошибок установки головок на требуемую дорожку поверхности дискаSeek_Error_Rate не имеет смысла для твердотельных дисков (SSD) и, соответственно, не поддерживается ими, а атрибут с идентификатором 9 ,характеризующий суммарное время работы накопителя за весь срок эксплуатации и обозначаемый как Power_On_Hours ,поддерживается как SSD, так и традиционными HDD.
Атрибуты состоят из нескольких полей, (наиболее часто обозначаемых как Val, Worst, Tresh, RAW ), каждое из которых является определенным показателем, характеризующим техническое состояние накопителя на данный момент времени. Программы считывания S.M.A.R.T. выводят содержимое атрибутов, как правило, в виде нескольких колонок:
Pre-Failure (PF, 01h)
- при достижении порогового значения данного типа атрибутов диск требует замены. Иногда данный бит флагов обозначают как Life Critical (CR)
или Pre-Failure warranty (PW)
O
nline test (OC, 02h)– атрибут обновляет значение при выполнении off-line/on-line встроенных
тестов SMART;
P
erfomance R
elated (PE или PR , 04h)– атрибут характеризует производительность;
E
rror R
ate (ER , 08h)– атрибут отражает счетчики ошибок оборудования;
E
vent C
ounts (EC, 10h) – атрибут представляет собой счетчик событий;
S
elf P
reserving (SP, 20h) – самосохраняющися атрибут;
Некоторые из программ могут интерпретировать флаги в виде текстовых описаний, близких по смыслу к рассмотренным выше. Один атрибут может иметь несколько установленных в единицу значений флагов,
например, атрибут с идентификатором 05
отражающий количество переназначенных из-за сбоев секторов из резервной области, имеет установленные флаги SP+EC+OC – самосохраняющийся,
счетчик событий, обновляется при автономном и интерактивном режиме накопителя.
Для анализа состояния накопителя, пожалуй самым важным значением атрибута является Value - условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, при достижения которого, производитель не гарантирует его работоспособность - поле Threshold . Если значение Value приближается или становится меньше значения Threshold , - накопитель пора менять.
Перечень атрибутов и их значения жестко не стандартизированы и некоторые из них могут определяться изготовителем накопителя, но основная часть интерпретируются одинаково. Например, атрибут с идентификатором 05 (Reallocated sector count ) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, как для устройств производства компании Seagate Technology, так и для устройств производства Western Digital . Набор поддерживаемых атрибутов зависит от модели накопителя и может значительно отличаться по составу для разных моделей.
Наиболее распространенным программным средством для получения данных S.M.A.R.T в среде Linux, является утилита smartctl из комплекта smartmontools , как правило, входящего в состав устанавливаемого по умолчанию программного обеспечения любого дистрибутива. При необходимости, обновить версию, а также скачать документацию на английском языке можно на сайте проекта smartmontools.org .
Для работы с утилитой smartctl требуются права суперпользователя root .
Формат командной строки smartctl :
smartctl параметры устройство
Примеры использования smartctl
smartctl –help или smartctl --usage - отобразить подсказку об использовании команды.
Параметры smartctl :
-V, --version, --copyright, --license - отобразить версию, информацию копирайта и лицензии.
-i, --info - отобразить идентификационную информацию для устройства.
-g NAME, --get=NAME - отобразить параметры настроек диска (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --all - отобразить все данные SMART указанного диска.
-x, --xall - отобразить все технические данные для указанного диска.
--scan - выполнить поиск дисковых устройств.
-q TYPE, --quietmode=TYPE установить режим детализации вывода для smartctl (errorsonly, silent, noserial)
-d TYPE, --device=TYPE - установить тип устройства (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N/E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) Обычно установка типа устройства требуется в тех случаях, когда утилита smartctl не может определить его автоматически.
-b TYPE, --badsum=TYPE - задать реакцию на обнаружение ошибок контрольных сумм (warn, exit, ignore)
-r TYPE, --report=TYPE - опция предназначена для разработчиков smartmontools и позволяет получить детализированную информацию при выполнении транзакций функции управления устройствами ввода/вывода ioctl (ioctl, ataioctl, scsiioctl и уровень отладки). Подробности - man smartctl
-n MODE, --nocheck=MODE - режим запрета на выполнение тестов для режимов энергосбережения (never, sleep, standby, idle). Обычно используется для предотвращения запуска шпиндельного двигателя по команде smartctl.
-s VALUE, --smart=VALUE - отключение или включение SMART (on/off)
-o VALUE, --offlineauto=VALUE - запрет или разрешение автоматического выполнения тестов в неинтерактивном режиме (в режиме простоя накопителя), принимаемые значения - on/off
-S VALUE, --saveauto=VALUE автосохранение атрибутов (on/off)
-s NAME[,VALUE], --set=NAME[,VALUE] - запрет/разрешение параметров оборудования накопителя (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --health - отобразить состояние накопителя (SMART health status)
-c, --capabilities - отобразить информацию о поддерживаемых возможностях SMART указанного жесткого диска.
-A, --attributes - отобразить атрибуты SMART
-f FORMAT, --format=FORMAT
- задать формат отображаемых атрибутов SMART (old, brief, hex[,id|val]). В основном, влияет на формат отображаемых значений идентификаторов атрибутов и формат отображения их флагов:
old
- идентификаторы атрибутов выводятся в десятичной системе счисления, значения флагов отображаются в шестнадцатеричной и интерпретируются в виде текста.
hex
- то же, что и в предыдущем случае, но идентификаторы атрибутов отображаются в шестнадцатеричной системе счисления.
brief
- компактный вывод, идентификаторы отображаются в десятичной системе счисления, флаги отображаются в виде символов с расшифровкой в нижней части таблицы:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029
. . . . . .
254 Free_Fall_Sensor -O--CK 100 100 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
-l TYPE, --log=TYPE - отобразить указанный журнал устройства (selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , --vendorattribute=N,OPTION - установить параметр для определенного производителем атрибута с идентификатором N
-F TYPE, --firmwarebug=TYPE - адаптация программы для учета ошибок в аппаратной прошивке накопителя (none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TYPE - предустановки параметров диска. По умолчанию, обнаружив информацию о накопителе в своей базе, утилита smartctl , использует набор параметров, доступный для данной модели. Опция use - использовать предустановки для данного накопителя, ignore - не использовать, show - отобразить предустановки для данного диска, showall - отобразить предустановки для указанной модели. Примеры:
smartctl –P ignore /dev/hdb
- игнорировать предустановки для диска /dev/hdb;
smartctl –P show /dev/sdb
- отобразить предустановки для указанного диска;
smartctl –P showall ‘ST9250315AS’
- - отобразить предустановки для указанной модели
диска - ST9250315AS;
smartctl –P showall ‘ST3750515AS’ ‘SD15’
- отобразить предустановки для указанной
модели диска ST3750515AS с прошивкой SD15;
-B [+]FILE, --drivedb=[+]FILE - прочитать и изменить базу данных моделей дисков из файла FILE. Знак “+” перед именем файла, означает добавление новых записей в базу, перед уже существующими.
По умолчанию, база данных хранится в файле /usr/share/smartmontools/drivedb.h
DEVICE SELF-TEST OPTIONS =====
-t TEST, --test=TEST - запустить выполнение теста TEST Run test. TEST: offline, short, long, conveyance, force, vendor,N, select,M-N, pending,N, afterselect,
-C, --captive - выполнение тестов в режиме захвата накопителя. Используется совместно с параметром -t для тестов не в режиме offline . Использование данного параметра может вызвать занятость устройства на все время выполнения теста и привести к нарушению работы системы и потере данных. Не стоит использовать опцию -c для выполнения тестов накопителей с монтированными разделами. Для SCSI устройств данная опция означает выполнение встроенных тестов в режиме "Foreground mode" .
-X, --abort - принудительно завершить тест, выполняющийся без ключа --captive .
Примеры использования smartctrl.
smartctl --info /dev/sdb - отобразить идентификационную информацию для устройства /dev/sdb. Пример вывода команды:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:31 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled
smartctl --all /dev/hdа - отобразить все данные SMART для устройства /dev/hda
Пример отображаемых данных:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:45 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (102) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x10bd) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 190274202 3 Spin_Up_Time 0x0003 096 096 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 72 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 070 060 030 Pre-fail Always - 11302732 9 Power_On_Hours 0x0032 073 073 000 Old_age Always - 24037 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 72 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Old_age Always - 19 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 38 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 73 194 Temperature_Celsius 0x0022 019 052 000 Old_age Always - 19 (0 14 0 0) 195 Hardware_ECC_Recovered 0x001a 118 100 000 Old_age Always - 190274202 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
smartctl -A -v 9,minutes /dev/hda - отобразить все данные атрибутов SMART для устройства /dev/hda и атрибут с идентификатором 9 (время нахождения во включенном состоянии) интерпретировать как внутреннее значение, задаваемое в минутах, а не в часах.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda - включить SMART для диска /dev/hda, разрешить автоматическое выполнение оффлайн-тестов и самосохранение атрибутов. Команду можно выполнять на работающей системе. Фактически, это установка стандартных параметров эксплуатации для обычного дискового накопителя.
smartctl --test=long /dev/hda
- выполнить расширенные встроенные тесты для диска /dev/hda.Команду можно использовать на работающей системе. Для просмотра результатов выполнения тестов используется команда вывода внутреннего журнала после завершения теста
smartctl -l selftest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had - отобразить данные внутреннего журнала самотестирования и атрибуты ошибок.
smartctl -s on -t offline /dev/hdc - включить SMART и выполнить оффлайн-тест для диска /dev/hdc. Если при тестировании будет обнаружена ошибка, то информация по ней будет записана во внутренний журнал, просмотреть который можно с использованием параметра -l error .
smartctl -q silent -a /dev/had - проверить данные SMART без вывода полученной информации.Обычно используется в скриптах. После выполнения команды проверяется код возврата (переменная $? командной оболочки)для определения факта выхода значения какого – либо атрибута за предельную величину или наличия записи об ошибках в журналах устройства.
smartctl -q errorsonly -H -l selftest /dev/had - выводить информацию только при наличии ошибочного состояния SMART или если какой-либо из внутренних тестов завершился с ошибкой.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda - выполнить внутренний тест в заданной области блоков LBA и после его завершения сканировать оставшуюся часть диска. Если при сканировании будет выполнено выключение питания, то продолжить его через 45 минут после включения.
smartctl --all --device=3ware,0 /dev/sda - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware.
smartctl -a -d 3ware,0 /dev/twe0 - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 6000/7000/8000.
smartctl -a -d 3ware,0 /dev/twa0 - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 9000
smartctl -t short -d 3ware,3 /dev/sdb - запустить выполнение коротких внутренних тестов для 4-го диска, второго дискового SCSI устройства /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda - получить данные SMART диска, подключенного к 3-му каналу первого контроллера HighPoint RocketRAID
Расшифровка атрибутов S.M.A.R.T
Идентификаторы атрибутов указаны в десятичной системе счисления, а в скобках они же – в шестнадцатеричной.
Оценка технического состояния жесткого диска по данным S.M.A.R.T
Набор атрибутов поддерживаемых конкретной моделью жесткого диска, даже если он минимален, позволяет с высокой достоверностью определить техническое состояние и перспективы эксплуатации устройства. Можно определить время нахождения во включенном состоянии по значению атрибута 9 , а в совокупности со значением атрибута 12 - количество включений /выключений электропитания, и следовательно, – круглосуточный или периодический режим эксплуатации. Интенсивность использования, температурный режим, негативные внешние воздействия – все эти факты легко отслеживаются по абсолютным значениям соответствующих атрибутов. Подобным же образом, можно оценить и уровень износа оборудования, качество поверхности и тракта записи/чтения.
Минимально информативный контроль состояния дисков может выполняться даже на уровне BIOS. В случае достижения критического значения любого атрибута, характеризующего работоспособность, при включенном мониторинге состояния S.M.A.R.T в настройках BIOS, загрузка операционной системы приостанавливается и на экран выводится сообщение:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить факт критического состояния накопителя средствами Базовой Системы Ввода-Вывода (BIOS) при включении компьютера.
Техническое состояние жесткого диска, не достигшее критического порога, характеризуется абсолютным значением атрибутов, отражающих счетчики сбоев, обнаруженных и исправленных оборудованием накопителя.
Изменение абсолютных значений атрибутов нужно рассматривать в динамике, и в логической взаимосвязи друг с другом.
Выполнение встроенных тестов S.M.A.R.T
Набор встроенных тестов S.M.A.R.T определяется производителем и может значительно отличаться для разных моделей жестких дисков. В основном, встроенные тесты SMART представлены короткими тестами (short self-test) и длинными (extended sels-test). Короткие тесты выполняют сканирование небольшой части дисковой поверхности, определенной производителем, и выполняются, в среднем, около 1 минуты. Длинные тесты выполняют сканирование всей рабочей поверхности диска и могут выполняться, в зависимости от быстродействия и объема диска, даже несколько часов. Также, для современных дисков, можно выполнять селективные тесты (selective self-test), параметры которых задаются пользователем и тесты после транспортировки устройства (conveyance self-test). Выполнение тестов можно прервать, если не задан режим захвата накопителя (captive) и накопитель поддерживает команду отмены теста. Что касается режима захвата накопителя при выполнении тестов captive , то пользоваться им нужно осторожно, если диск используется системой.
Примеры:
smartctl --test=short /dev/sdb - запустить короткий тест. В ответ на команду, будет выведена информация:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode". Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun (previous test aborted). Please wait 1 minutes for test to complete. Test will complete after Fri Dec 5 16:08:09 2014 Use smartctl -X to abort test.
Что означает, что диску отправлена команда на выполнение короткого теста, диск ее воспринял успешно, тест будет продолжаться 1 минуту, и для принудительного его прекращения можно воспользоваться командой smartctl –X.
Результат выполнения теста можно проверить, просмотрев журнал тестов командой smartctl –l selftest . В ответ будет получена информация журнала selftest :
=== START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 831 -
Колонки журнала:
Num
- номер записи.
Test_Description
- описание теста.
Status
- статус завершения (выполнен без ошибок)
Remaining
- процент оставшегося времени до завершения теста, если он еще не завершен (00%)
LifeTime(hours)
- время работы накопителя с начала эксплуатации.
LBA_of_first_error
- номер логического блока LBA где обнаружена первая ошибка при выполнении теста. В данном примере, ошибок нет.
Для запуска длинного теста используется команда:
smartctl --test=long /dev/sdb
В ответ на команду выводится информация о начале теста:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Extended self-test routine immediately in off-line mode". Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 70 minutes for test to complete. Test will complete after Fri Dec 5 17:15:44 2014
Как видно, длинный тест для данной модели накопителя будет выполняться 70 минут.
Результат выполнения можно проверить командой smartctl –l selftest /dev/sda
Список команд ATA для работы с S.M.A.R.T
SMART_READ_VALUES 0xd0 SMART_READ_THRESHOLDS 0xd1 SMART_AUTOSAVE 0xd2 SMART_SAVE 0xd3 SMART_IMMEDIATE_OFFLINE 0xd4 SMART_READ_LOG_SECTOR 0xd5 SMART_WRITE_LOG_SECTOR 0xd6 SMART_ENABLE 0xd8 SMART_DISABLE 0xd9 SMART_STATUS 0xda SMART_AUTO_OFFLINE 0xdb
Дополнительно по теме оборудования в Linux:
Сегодня, хотелось бы чуточку подробнее поговорить о вскользь упомянутой в предыдущей статье о критериях выбора винчестера технологии SMART, а также выяснить вопрос о появлении плохих секторов при проверке поверхности специальными программами и исчерпании резервной поверхности для их переназначения - вопросу, поднятому на из прошлой статьи.
Для начала как всегда краткий исторический экскурс. Надежность жесткого диска (и любого устройства хранения в самом общем случае) всегда придается огромное значение. И дело отнюдь не в его стоимости, а в ценности той информации, которую он уносит с собой в мир иной, уходя из жизни сам, и в потерях прибыли, связанных с простоями при выходе из строя винчестеров, если речь идет о бизнес-пользователях, даже в том случае, если информация осталась. И вполне естественно, что о таких неприятных моментах хочется знать заранее. Даже обычные рассуждения на бытовом уровне подсказывают, что наблюдение за состоянием прибора в работе, может подсказать такие моменты. Осталось только каким-то образом реализовать это наблюдение в винчестере.
Впервые над этой задачей задумались инженеры голубого гиганта (IBM то бишь). И в 1995 году они предложили технологию, отслеживающую несколько критически важных параметров накопителя, и делающую попытки на основании собранных данных предсказать выход его из строя - Predictive Failure Analysis (PFA). Идею подхватила Compaq, которая чуть позже создала свою технологию - IntelliSafe. В разработке Compaq также поучаствовали Seagate, Quantum и Conner. Созданная ими технология также отслеживала ряд рабочих характеристик диска, сравнивала их с допустимым значением и рапортовала хост-системе в случае наличия опасности. Это был огромный шаг вперед если и не в повышении надежности винчестеров, то хотя бы в уменьшении риска потери информации при их использовании. Первые попытки оказались удачными, и показали необходимость дальнейшего развития технологии. Уже в объединении всех крупных производителей жестких дисков появилась технология S.M.A.R.T (Self Monitoring Analysing and Reporting Technology), базирующаяся на технологиях IntelliSafe и PFA (кстати говоря, PFA существует и поныне, как набор технологий для наблюдения и анализа за различными подсистемами серверов IBM, в том числе и дисковой подсистемой, причем наблюдение за последней базируется именно на технологии SMART).
Итак, SMART - это технология внутренней оценки состояния диска, и механизм предсказания возможного выхода из строя жесткого диска. Важно отметить то, что технология в принципе не решает возникающих проблем (основные из них показаны на рисунке чуть ниже), она способна лишь предупредить об уже возникшей проблеме либо об ожидающейся в ближайшем времени.
При этом нужно также сказать, что технология не в состоянии предсказать абсолютно все возможные проблемы и это логично: выход электроники в результате скачка напряжения, порча головок и поверхности в результате удара и т.п. никакая технология предсказать не в силах. Предсказуемы лишь те проблемы, которые связаны с постепенным ухудшением каких-либо характеристик, равномерной деградацией каких либо компонент.
Этапы развития технологии
В своем развитии технология SMART прошла три этапа. В первом поколении было реализовано наблюдение небольшого числа параметров. Никаких самостоятельных действий накопителя не предусматривалось. Запуск осуществлялся только командами по интерфейсу. Спецификации описывающей стандарт полностью нет, и, следовательно, не было и нет и четкого предначертания, о том, какие именно параметры надлежит контролировать. Более того, их определение и определение допустимого уровня их снижения целиком и полностью предоставлялся производителям винчестеров (что естественно в силу того, что производителю виднее что именно надлежит контролировать данном его винчестере, ибо все винчестеры слишком различны). И программное обеспечение, по этой причине, написанное, как правило, сторонними фирмами, не было универсальным, и могло ошибочно рапортовать о предстоящем сбое (путаница возникала из-за того, что под одним и тем же идентификатором различные производители хранили значения различных параметров). Имело место большое число жалоб на то, что число случаев обнаружения пред сбойного состояния чрезвычайно мало (особенности человеческой природы: получать хочется все и сразу, жаловаться на внезапные отказы дисков до внедрения SAMRT в голову как-то никому не приходило). Ситуация усугубилась еще и тем, что в большинстве случаев не были выполнены минимально необходимые требования для функционирования SMART (об этом поговорим позже). Статистика говорит о том, что число предсказываемых сбоев было менее 20%. Технология на этом этапе была далека от совершенства, но являлась революционным шагом вперед.
О втором этапе развития SMART - SMART II известно также не много. В основном наблюдались те же проблемы, что и с первой. Нововведениями являлись возможность фоновой проверки поверхности, выполняемая диском в автоматическом режиме при простоях и ведение журналов ошибок, расширился список контролируемых параметров (снова же в зависимости от модели и производителя). Статистика говорит о том, что число предсказываемых сбоев достигло 50%.
Современный этап представлен технологией SMART III. На ней остановимся подробней, попытаемся разобраться в общих чертах как она работает, что и зачем в ней нужно.
Нам уже известно, что SMART производит наблюдение за основными характеристиками накопителя. Эти параметры называются атрибутами. Необходимые к мониторингу параметры определяются производителем. Каждый атрибут имеет какую-то величину - Value. Обычно изменяется в диапазоне от 0 до 100 (хотя может быть в диапазоне до 200 или до 255), ее величина - это надежность конкретного атрибута относительно некоторого его эталонного значения (определяется производителем). Высокое значение говорит об отсутствии изменений данного параметра или, в зависимости от значения, его медленном ухудшении. Низкое значение говорит о быстрой деградации или о возможном скором сбое, т.е. чем выше значение Value атрибута, тем лучше. Некоторыми программами мониторинга выводится значение Raw или Raw Value - это значение атрибута во внутреннем формате (который так же различен у дисков разных моделей и разных производителей), в том, в котором он хранится в накопителе. Для простого пользователя он малоинформативен, больший интерес представляет посчитанное из него значение Value. Для каждого атрибута производителем определяется минимальное возможное значение, при котором гарантируется безотказная работа накопителя - Threshold. При значении атрибута ниже величины Threshold очень вероятен сбой в работе или полный отказ. Осталось только добавить, что атрибуты бывают критически важными и некритически. Выход критически важного параметра за пределы Threshold фактический означает выход из строя, выход за переделы допустимых значений некритически важного параметра свидетельствует о наличии проблемы, но диск может сохранять свою работоспособность (хотя, возможно, с некоторым ухудшением некоторых характеристик: производительности например).
К наиболее часто наблюдаемым критически важным характеристикам относятся: Raw Read Error Rate - частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска.
Spin Up Time - время раскрутки пакета дисков из состояния покоя до рабочей скорости. При расчете нормализованного значения (Value) практическое время сравнивается с некоторой эталонной величиной, установленной на заводе. Не ухудшающееся немаксимальное значение при Spin Up Retry Count Value = max (Raw равном 0) не говорит ни о чем плохом. Отличие времени от эталонного может быть вызвано рядом причин, например блок питания подкачал.
Spin Up Retry Count - число повторных попыток раскрутки дисков до рабочей скорости, в случае если первая попытка была неудачной. Ненулевое значение Raw (соответственно немаксимальное Value) свидетельствует о проблемах в механической части накопителя.
Seek Error Rate - частота ошибок при позиционировании блока головок. Высокое значение Raw свидетельствует о наличии проблем, которыми могут являться повреждение сервометок, чрезмерное термическое расширение дисков, механические проблемы в блоке позиционирования и др. Постоянное высокое значение Value говорит о том, что все хорошо.
Reallocated Sector Count - число операций переназначения секторов. SMART в современных способен произвести анализ сектора на стабильность работы "на лету" и в случае признания его сбойным произвести его переназначение. Ниже мы поговорим об этом подробнее.
Из некритических, так сказать информационных атрибутов, обычно производят наблюдение за следующими:
Все происходящие ошибки и изменения параметров фиксируются в журналах SMART. Эта возможность появилась уже в SMART II. Все параметры журналов - назначение, размер, их число определяются изготовителем винчестера. Нас с вами в настоящий момент интересует только факт их наличия. Без подробностей. Информация хранящаяся в журналах используется для анализа состояния и составления прогнозов.
Если не вдаваться в подробности, то работа SMART проста - при работе накопителя просто отслеживаются все возникающие ошибки и подозрительные явления, которые находят отражение в соответствующих атрибутах. Кроме того начиная так же со SMART II у многих накопителей появились функции самодиагностики. Запуск тестов SMART возможен в двух режимах, off-line - тест выполняется фактически в фоновом режиме, так как накопитель в любое время готов принять и выполнить команду, и монопольном при котором при поступлении команды, выполнение теста завершается.
Документировано существует три типа тестов самодиагностики: фоновый сбор данных (Off-line collection), сокращенный тест (Short Self-test), расширенный тест (Extended Self-test). Два последних способны выполняться как в фоновом, так и в монопольном режимах. Набор тестов в них входящих не стандартизирован.
Продолжительность их выполнения может быть от секунд до минут и часов. Если вы вдруг не обращаетесь к диску, а он при этом издатет звуки как и при рабочей нагрузке - он просто похоже занимается самоанализом. Все данные собранне в результате таких тестов будут также сохранены в журналах и аттрибутах.
Ох уж эти плохие сектора...
Теперь вернемся к вопросу бэд-секторов, с которых все началось. В SMART III появилась функция, позволяющая прозрачно для пользователя переназначать BAD сектора. Работает механизм достаточно просто, при неустойчивом чтении сектора, или же ошибки его чтения, SMART заносит его в список нестабильных и увеличит их счетчик (Current Pending Sector Count). Если при повторном обращении сектор будет прочитан без проблем, он будет выброшен из этого списка. Если же нет, то при предоставившейся возможности - при отсутствии обращений к диску, диск начнет самостоятельную проверку поверхности, в первую очередь подозрительных секторов. Если сектор будет признан сбойным, то он будет переназначен на сектор из резервной поверхности (соответственно RSC увеличиться). Такое фоновое переназначение приводит к тому, что на современных винчестерах сбойные секторы практически никогда не видны при проверке поверхности сервисными программами. В тоже время, при большом числе плохих секторов их переназначение не может происходить до бесконечности. Первый ограничитель очевиден - это объем резервной поверхности. Именно этот случай я имел ввиду. Второй не столь очевиден - дело в том, что у современных винчестеров есть два дефект-листа P-list (Primary, заводской) и G-list (Growth, формируется непосредственно во время эксплуатации). И при большом числе переназначений может оказаться так, что в G-list не оказывается места для записи о новом переназначении. Эта ситуация может быть выявлена по высокому показателю переназначенных секторов в SMART. В этом случае еще не все потеряно, но это выходит за рамки данной статьи.
Итак, используя данные SMART даже не нося диск в мастерскую можно довольно точно сказать, что с ним происходит. Существуют различные технологии-надстройки над SMART, которые позволяют определить состояние диска еще более точно и практически достоверно причину его неисправности. Об этих технологиях мы поговорим в отдельной статье.
Нужно знать, что приобретения накопителя со SMART не достаточно, для того, что бы быть в курсе всех происходящих с диском проблем. Диск, конечно, может следить за своим состоянием и без посторонней помощи, но он не сможет сам предупредить в случае приближающейся опасности. Нужно что-то, что позволит на основании данных SMART выдать предупреждение. (обычная цепочка приведена на рисунке чуть ниже).
Как вариант возможен BIOS, который при загрузке при включенной соответствующей опции проверяет состояние SMART накопителей. А если же вам хочется вести постоянный контроль за состоянием диска, необходимо использовать какую-то программу мониторинга. Тогда вы сможете видеть информацию в подробном и удобном виде.

SmartMonitor из HDD Speed работающий под DOS

SIGuiardian, работающая из Windows
Об этих программах мы также поговорим в отдельной статье. Именно это я имел ввиду, когда говорил о том, что по началу не выполнялись необходимые требования при эксплуатации жестких дисков с SMART .
Технологии хранения информации:
Технология NoiseGuardMагнито-оптические технологии
Доброго времени суток!
Сколько бы всего можно было исправить, если бы знать заранее, что нас поджидает...
И если в жизни предугадать некоторые события практически нереально, то вот в случае с жестким диском - часть проблем всё же, предугадать и предвидеть можно!
Для этого существуют специальные утилиты, которые могут узнать и проанализировать показания SMART* диска (показать их вам, если необходимо), и на основе этих данных оценить состояние здоровья вашего диска, попутно рассчитав сколько лет он еще сможет прослужить.
Информация крайне полезная, к тому же подобные утилиты могут вести мониторинг вашего диска в режиме онлайн, и как только появятся первые признаки нестабильной работы - тут же вас оповестить. Соответственно, вы вовремя успеете сделать бэкап и принять меры (хотя бэкап нужно делать всегда, даже когда все хорошо 😊).
И так, рассмотрю в статье несколько способов (и несколько утилит) анализа состояния HDD и SSD.
* Примечание:
S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) - специальная технология оценки состояния жёсткого диска системой интегрированной аппаратной самодиагностики/самонаблюдения. Основная задача - определить вероятность выхода устройства из строя, предотвратив потерю данных.
Пожалуй, это один из самых популярных вопросов, которые задают все пользователи, впервые столкнувшиеся с проблемами с жестким диском (либо задумавшиеся о безопасности хранения своих данных). Всех интересует время, которое проработает диск до полной "остановки". Попробуем предсказать...
Поэтому, в первой части статьи я решил показать пару утилит, которые могут получить все показания с диска и проанализировать их самостоятельно, а вам дать лишь готовый результат (во второй части статьи, приведу утилиты для просмотра показаний SMART для самостоятельного анализа).
Способ №1: с помощью Hard Disk Sentinel
Одна из лучших утилит для мониторинга состояния дисков компьютера (как жестких дисков (HDD), так и "новомодных" SSD). Что больше всего подкупает в программе - она все данные, полученные о состоянии диска самостоятельно проанализирует и покажет Вам уже готовый результат (очень удобно для начинающих пользователей).
Чтобы не быть голословным, покажу сразу же главное окно программы, которое появляется после первого запуска (анализ диска будет сделан сразу автоматически). Здоровье и производительность диска оцениваются как 100% (в идеале, так и должно быть), время, которое диск еще проработает в нормальном режиме оценивается программой примерно в 1000 дней (~3 лет).

Что с диском по версии Hard Disk Sentinel
Кроме этого, программа позволяет следить за температурой: как за текущей, так и за средней и максимальной в течении дня, недели, месяца. В случае выхода температуры за пределы "нормальности" - программа предупредит Вас об этом (что тоже очень удобно).
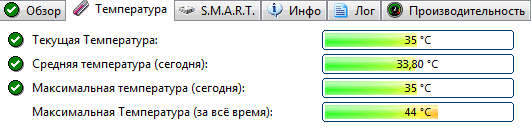
Также Hard Disk Sentinel позволяет просмотреть показания SMART (правда, чтобы оценить их, нужно неплохо разбираться в дисках), получить полную информацию о жестком диске (модель, серийной номер, производитель и пр.), посмотреть, чем жесткий диск загружен (т.е. получить сведения о производительности).
В общем и целом, на мой скромный взгляд, Hard Disk Sentinel - это одна из лучших утилит за контролем состояния дисков в системе. Стоит добавить, что есть несколько версий программ: профессиональная и стандартная (для профессиональной версии с расширенным функционалом - есть портативная версия программы, не нуждающаяся в установке (например, ее можно даже запускать с флешке)).
Hard Disk Sentinel работает во всех популярных Windows (7, 8, 10 - 32|64 bits), поддерживает русский язык в полном объеме.
Способ №2: с помощью HDDlife
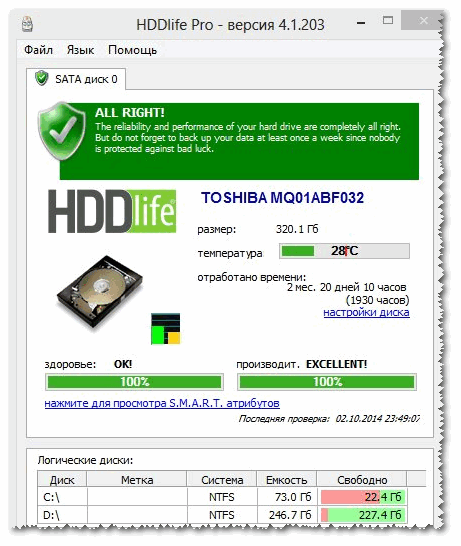
Эта программа аналогична первой, также наглядно показывает текущее состояние диска: его здоровье и производительность (в процентном выражении), его температуру, количество отработанного времени (в месяцах). В верхней части окна, на основе всех этих данных, HDDlife показывает итоговое резюме по вашему диску, например, в моем случае "ALL RIGHT" (что значит, что с диском все в порядке).
Кстати, программа может работать в режиме онлайн, следя за состоянием вашего диска, и в случае, если что-то пойдет не так (при появлении первых признаков проблем) - сразу же известить вас об этом.
В качестве примера ниже на скриншоте показан SSD-диск получил предупреждение: его состояние еще в допустимых пределах, но надежность и производительность ниже среднего значения. В этом случае доверять диску какие-либо важные данные не стоит, и по возможности, нужно готовиться к его замене.

Кстати, в главном окне программы, рядом с количеством отработанного времени диска, есть ссылка "Настойка диска" (позволяет изменить некоторые нужные параметры). Открыв ее, можно управлять балансом между шумом/производительностью) очень полезно с дисками, которые сильно шумят), и настроить параметры энергопотребления (актуально для ноутбуков, у которых быстро садится батарея).

Дополнение : HDDlife работает как на ПК, так и на ноутбуках. Поддерживает HDD и SSD диски. Есть в наличие портативные версии программы, не нуждающиеся в установке. Можно настроить так, чтобы программа запускалась вместе с вашей Windows. HDDlife работает в Windows: XP, 7, 8, 10 (32|64 bits).
Как посмотреть показания SMART
Если предыдущие утилиты самостоятельно оценивали состояние диска, на основе данных SMART, то нижеприведенные утилиты предоставят вам больше свободы и данных для самостоятельного анализа. В отчетах можно будет найти достаточно большой набор параметров, на основе которых - можно будет примерно оценить состояние диска и сделать прогноз по его дальнейшей работе.
Способ №1: с помощью СrystalDiskInfo
СrystalDiskInfo
Отличная бесплатная утилита для просмотра состояния и показаний SMART жесткого диска (поддерживаются в том числе и SSD-диски). Чем подкупает утилита - она предоставляет вам полную информацию о температуре, техническому состоянию диска, его характеристиках и пр., причем, часть данных идут с пометками (т.е. утилита актуальна, как для опытных пользователей, которые сами знают "что-есть-что", так и для начинающих, которым нужна подсказка).
Например, если с температурой что-то не так - то вы увидите на ней красный индикатор, т.е. СrystalDiskInfo сам вам об этом сообщит.

Главное окно программы условно можно разбить на 4 зоны (см. скриншот выше):
- "1" - здесь указаны все ваши физические диски, установленные в компьютере (ноутбуке). Рядом с каждым показана его температура, техсостояние, и кол-во разделов на нем (например, "C: D: E: F:");
- "2" - здесь показана текущая температура диска и его техсостояние (программа делает анализ на основе всех полученных данных с диска);
- "3" - данные о диске: серийный номер, производитель, интерфейс, скорость вращения и пр.;
- "4" - показания SMART. Кстати, чем подкупает программа - вам необязательно знать, что означает тот или иной параметр - если что-то не так с каким-либо пунктом, программа его пометит желтым или красным цветом и известит вас об этом.
В качестве примера к вышесказанному, приведу скриншот, на котором отображены два диска: слева - с которым все нормально, справа - у которого есть проблемы с переназначенными секторами (техсостояние - тревога!).

В качестве справки (о переназначенных секторах):
когда жесткий диск обнаруживает, например, ошибку записи, он переносит данные в специально отведённую резервную область (а сектор этот будет считаться «переназначенным»). Поэтому на современных жёстких дисках нельзя увидеть bad-блоки - они спрятаны в переназначенных секторах. Этот процесс называют remapping , а переназначенный сектор - remap .
Чем больше значение переназначенных секторов - тем хуже состояние поверхности дисков. Поле "raw value" содержит общее количество переназначенных секторов.
Кстати, для многих производителей дисков, даже один переназначенный сектор - это уже гарантийный случай!
Чтобы утилита CrystalDiskInfo следила в режиме онлайн за состоянием вашего жесткого диска - в меню "Сервис" поставьте две галочки: " Запуск агента" и "Автозапуск" (см. скрин ниже).

Затем вы увидите значок программы с температурой рядом с часами в трее. В общем-то, за состояние диска теперь можно быть более спокойным ☺...

Способ №2: с помощью Victoria
Victoria - одна из самых знаменитых программ для работы с жесткими дисками. Основное предназначение программы оценить техническое состояние накопителя, и заменить поврежденные сектора на резервные рабочие.
Утилита бесплатна и позволяет работать как из-под Windows, так и из-под DOS (что во многих случаях показывает гораздо более точные данные о состоянии диска).
Из минусов : работать с Викторией достаточно сложно, по крайней мере, наугад нажимать в ней кнопки я крайне не рекомендую (можно легко уничтожить все данные на диске).
У меня на блоге есть одна достаточно простая статья (для начинающих), где подробно разобрано, как проверить диск с помощью Виктории (в том числе, узнать показания SMART - пример на скриншоте ниже (на котором Виктория указала на возможную проблему с температурой)).
👉 В помощь!
Быстрая диагностика диска в Victoria:

Во всех современных накопителях последних лет абсолютно любого производителя присутствует система SMART (self-monitoring, analysis and reporting technology - технология предупреждения, анализа и самопроверки) жесткого диска, очень тесно связанная с функционированием накопителя.
Современные технологии SMART осуществляют: мониторинг различных параметров состояния диска, сканирование поверхности жесткого диска с дальнейшей автоматической заменой нечитаемых секторов и занесение их в error-log, т.н. список, где номера этих секторов хранятся в виде таблицы, периодическое повторное сканирование "ненадежных" секторов из error-log и, если система определяет, что данный сектор исправен - то исключает его из данного списка и он становится доступен на поверхности для пользовательской информации (но также помечается для дальнейшей перепроверки при следующем сканировании поверхности), либо, если сектор не прочитывается несколько раз подряд, не переписывается, то он отправляется в следующий дефект-лист,именуемый у разных производителей по-разному, но имеющий одинаковое предназначение - этот лист является как бы посредником между error-log таблицей и финальным G-листом, где дефект уже будет занесен в G-лист навсегда, станет отображаться в SMART, в строке current pending sectors/offline UNC sectors.
Из статуса current pending поврежденный сектор после очередной перепроверки на "живучесть", если не прошел чтение/запись, то окончательно отправляется в статус переназначенных и там уже остается. Диск в дальнейшей работе его уже не использует, не тестирует повторно на чтение/запись.
В строке reallocated sector count изменяется значение с N на N+1.
Если накопитель имеет уже серьёзные повреждения, то при загрузке компьютера может выводиться надпись: «smart status bad backup and replace». Это значит, что статус SMART жёсткого диска изменился из состояния GOOD в состояние BAD, на диске как минимум имеются BAD-блоки и состояние диска продолжает ухудшаться. Пользователю рекомендуется сохранить свои данные, если они ещё доступны для чтения и заменить жёсткий диск на новый.
SMART ВЫГЛЯДИТ ТАК:
Выводится в виде таблицы со следующими столбцами:
ID – ИДЕНТИФИКАЦИОННЫЙ НОМЕР ПАРАМЕТРА
Name – выводимое программой имя параметра
VAL – НОРМАЛИЗОВАННОЕ ЗНАЧЕНИЕ ПАРАМЕТРА (НОРМАЛИЗОВАННОЕ ЗНАЧИТ, В ДАННОМ СЛУЧАЕ, ЧТО ВНУТРЕННЕЕ (RAW) ЗНАЧЕНИЕ ПАРАМЕТРА ПРЕОБРАЗОВАНО ПО ОПРЕДЕЛЁННОМУ АЛГОРИТМУ ДЛЯ БОЛЕЕ УДОБНОГО И ПОНЯТНОГО ПРОСМОТРА ЗНАЧЕНИЯ. НАПРИМЕР, ВНУТРЕННИЙ ПАРАМЕТР ВСЕГДА УВЕЛИЧИВАЕТСЯ И МОЖЕТ ПРИНИМАТЬ ЗНАЧЕНИЕ В НЕСКОЛЬКО ТЫСЯЧ ЕДИНИЦ, А ВЫВОДИМОЕ ЗНАЧЕНИЕ ИЗМЕНЯЕТСЯ ОТ 100 ДО 0 И ОТОБРАЖЕНИЕ ВНУТРЕННЕГО ДИАПАЗОНА ИЗМЕНЕНИЯ ПАРАМЕТРА НА ВЫВОДИМЫЙ И ЕСТЬ, В ДАННОМ СЛУЧАЕ, НОРМАЛИЗАЦИЯ)
Wrst – худшее значение параметра за отрезок времени время
Thresh – пороговое значение, при достижении которого диск рекомендуется заменить
РАССМОТРИМ, КАКИЕ СУЩЕСТВУЮТ ПАРАМЕТРЫ В СИСТЕМЕ SMART. НАБОР ОТСЛЕЖИВАЕМЫХ ПАРАМЕТРОВ ЗАВИСИТ ОТ ПРОИЗВОДИТЕЛЯ ДИСКА И НЕ ВСЕ ИЗ ПЕРЕЧИСЛЕННЫХ БУДУТ ПРИСУТСТВОВАТЬ В ВАШЕМ СЛУЧАЕ.
Атрибуты SMART:
1 Raw read error rate - количество ошибок при считывании секторов с пластин.
2 Throughput Performance - общая производительность диска в относительных единицах.
3 Spin-up time - время раскрутки пластин от нуля до номинальной скорости вращения в миллисекундах
4 Number of spin-up times - количество циклов раскрутки/остановки пластин; отражает механический ресурс диска из-за ограниченного количества циклов запуска/останова.
5 Reallocated sector count - параметр отражает количество запасных секторов; когда диск находит ошибку чтения/записи/проверки, он переназначает плохой сектор на хороший из запасной зоны; нормализованное значение атрибута уменьшается по мере убывания запасных секторов; RAW-значение показывает количество преназначенных секторов, которое в норме должно быть ноль; на SSDRAW значение показывает количество неисправных блоков флеш-памяти.
6 Read Channel Margin - данный атрибут не используется в современных накопителях.
7 Seek error rate - количество ошибок позиционирования магнитных головок.
8 Seek Time Performance - средняя скорость позиционирования привода магнитных головок на указанный сектор; в SSDпараметр не используется
9 Power-on time - ожидаемое время жизни диска, основанное на времени, проведённом во включённом состоянии; нормализованное значение уменьшается со 100 до 0, связано с ресурсом диска; уменьшение этого параметра косвенно говорит о состоянии механики диска
10 Spin-up retries - количество попыток раскруток пластин при условии, что первая попытка была неудачная; считается с момента начала использования; на SSD не используется
12 Start/stop count - ожидаемое время жизни, основанное на количестве пусков/остановов пластин; каждый диск имеет ограниченное количество пусков/остановов, параметр уменьшается со 100 до 0; RAW значение показывает число включений/выключений
13 Soft Read Error Rate - у одних производителей этот параметр описывается, как указывающий на количество ошибок, не восстановленных ECC, а у других наоборот - восстановленных
100 Erase/Program Cycles - общее количество циклов чтения/записи для всей флеш-памяти за весь срок службы; SSD имеет ограничение на количество циклов чтения/записи, конкретное значение зависит от типа и производителя микросхем флеш-памяти
103 Translation Table Rebuild - количество событий перестроения внутренней таблицы адресов блоков при её повреждении и восстановлении; RAW значение показывает актуальное количество данных событий
170 Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
171 Program Fail Count - количество случаев неудавшейся записи блока флеш-памяти
172 Erase Fail Count - количество случаев неудавшейся операции стирания блока флеш-памяти
173 Wear Leveller Worst Case Erase Count - максимальное количество операций стирания, произведённых над блоком флеш-памяти
178 Used Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
180 Unused Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество неиспользованных резервных блоков
183 SATA Downshifts - показывает, как часто требовалось понизить скорость передачи по SATA (с 6Гб/c до 3Гб/с или 1.5Гб/с) для успешной передачи данных, при уменьшении значения атрибута следует заменить кабель
184 End-to-End error - количество ошибок, возникших в буфере диска; часть технологии HP SMART IV; может свидетельствовать о неисправности RAM-буффера диска
185 Head Stability - по атрибуту нет достоверной информации
186 Induced Op-Vibration Detection - по атрибуту нет достоверной информации
187 Reported UNC error - количество нескорректированных ошибок чтения
188 Command timeout - количество невыполненных диском команд из-за истечения времени ожидания
189 High Fly writes - количество ошибок записи, вызванных неправильной высотой полёта магнитной головки над поверхностью
190 Airflow temperature - температура воздуха внутри гермоблока HDD
191 G-Sense Errors - указывает сколько раз диск прерывал работу из-за ударов или вибрации
192 power-off retract cycles - количество неожиданных пропаданий питания, когда оно пропадало прежде, чем была получена команда на отключение диска; у hdd срок службы при неожиданном отключении значительно меньше, чем при нормальном; у ssd есть риск потери таблицы внутреннего состояния при неожиданном пропадании питания
193 load/unload cycles - количество перемещений бмг между зоной парковки и зоной данных; значение уменьшается от 100 до 0, raw содержит актуальное количество перемещений
194 hda temperature- температура блока магнитных головок
195 hardware ecc recovered- количество ошибок чтения, скорректированных кодом коррекции ошибок
196 reallocation events - общее количество переназначений секторов, включает и off-line сканирование и обычную работу
197 current pending sectors- количество нестабильных секторов, ожидающих перепроверки и, возможно, переназначения
198 offline scan unc sectors- количество плохих секторов, найденных диском при фоновом самосканировании; ухудшение этого параметра говорит о быстрой деградации поверхности
199 ultra dma crc errors- количество ошибок при передаче данных между диском и материнской платой; при ухудшении этого параметра стоит заменить кабель
200 write error rate - частота возникновения ошибок при записи
202 data address mark errors - количество ошибок при поиске запрошенного сектора
203 run out cancel - количество ошибок, вызванных неверной контрольной суммой при попытке коррекции ошибки
204 soft ecc corrections - количество ошибок, скорректированных кодом коррекции
206 flying height - девиация высоты полёта головки над поверхностью относительно оптимального значения; если головка слишком низко, она может повредить поверхность, если слишком высоко - увеличивается количество ошибок чтения
207 spin high current - величина тока, требуемая для раскрутки пластин
209 offline seek performance - производительность подсистемы поиска при выполнении off-line сканирования
220 disk shift - расстояние, на которое сместился пакет пластин относительно теоретического положения в результате механического повреждения или перегрева
227 torque amplification count - показывает сколько раз требовалось подавать увеличенный ток для раскрутки пластин
230 gmr head amplitude - амплитуда колебаний головок бмг
233 media wearout indicator - остаток ресурса памяти в ssd
240 head flying hours- время, проведённое головками в зоне пользовательских данных; значение уменьшается, обычно от 100 до 0
241 total lbas written - количество 512-и байтных блоков, записанных за всю жизнь устройства
242 total lbas read - количество 512-и байтных блоков, считанных за всю жизнь устройства
250 read error retry rate
Сложность интерпретации значений smart состоит в том, что ни на количество, ни на тип, ни на значения, ни на единицы измерения отслеживаемых параметров нет единого стандарта. поэтому реализация smart всегда зависит от конкретного производителя. нормализацию raw-значений в показатели атрибутов все делают по-своему, а результатом является статус проверки smart good или bad. поэтому достоверный вывод о состоянии диска можно сделать только проверив его поверхность какой-либо диагностической программой. но если нужно быстро оценить состояние диска и возможные проблемы, нужно обратить внимание на несколько основных, самых информативных атрибутов.
Наиболее важные аттрибуты smart:
5 reallocated sectors count - количество переназначенных секторов; рост значения этого атрибута свидетельствует об ухудшении состояния поверхности диска
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number ) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 0x | |||||||||||||||||
| 0x | |||||||||||||||||
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение , а используемый вместо повреждённого сектор — переназначенным . Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет:)
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap . Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.

В случае неудачи чтения как с remap , так и с Advanced remap , стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!

Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
Атрибут: 202 (СА) Data Address Mark Error
Атрибут: 203 (CB) Run Out Cancel
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения :
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
А так выглядит он же в «правильной» HDDScan 3.3:
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина .
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:

Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах . При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).