Перед тем, как что-то делать в интернете: создавать сайт, настраивать рекламную компанию, писать статью или книгу, надо посмотреть, что вообще ищут люди, чем интересуются, что вводят в поисковой строке.
Поисковые запросы (ключевые фразы и слова) чаще всего собирают в двух случаях:
- Перед созданием сайта. В этом случае нужно собрать максимум ключевых слов, чтобы охватить всю вашу сферу. После сбора, поисковые запросы анализируются и на основании этого принимается решение о структуре сайта.
- Для настройки контекстной рекламы. Для рекламы выбирают не все, а только слова, по которым можно определить интерес к товару или услуге, желательно активный интерес выраженный словами «купить», «цена», «заказать» и т.п.
Если вы собираетесь настраивать контекстную рекламу, то .
А ниже мы рассмотрим, как собрать статистику поисковых запросов в популярных поисковых системах, а так же небольшие секреты, как это сделать лучше.
Как посмотреть статистику запросов Яндекс
У поисковой системы Яндекс есть специальный сервис «Подбор слов», находящийся по адресу http://wordstat.yandex.ru/ . Пользоваться им очень просто: вводим любые слова и обычно, кроме статистики по этим словам, также видим что искали вместе с этими словами.
Очень важно понимать, что статистика по более коротким запросам, включает в себя статистику всех подробных запросов с этими словами. Например, на скриншоте запрос «статистика запросов» включает в себя запрос «статистика запросов яндекс» и все остальные запросы ниже.
В правой колонке отображаются запросы, которые искали люди, искавшие введенный вами запрос. Откуда берется эта информация? Это запросы, которые были введены до вашего запроса или сразу после него.
Чтобы посмотреть точное количество запросов по фразе, надо ввести ее в кавычках «фраза». Так, конкретно запрос «статистика запросов» искали 5047 раз.

Как посмотреть статистику поисковых запросов Google
С недавних пор для России стал доступен инструмент Гугл Тренды, он находится по адресу http://www.google.com/trends/ . Он выводит популярные в последнее время поисковые запросы. Вы можете ввести любой свой запрос, чтобы оценить его популярность.

Кроме частоты запросов, Google покажет популярность по регионам и схожие запросы.
Второй способ посмотреть частоту поисковых запросов Гугл — это использовать сервис для рекламодателей adwords.google.ru. Для этого нужно зарегистрироваться как рекламодатель. В меню «инструменты» нужно выбрать «Планировщик ключевых слов» и дальше «Получить статистику запросов».

В планировщике, кроме статистики, вы узнаете уровень конкуренции рекламодателей по этому запросу и даже примерную стоимость клика, если решите тоже рекламироваться. К слову, стоимость обычно завышена.
Статистика поисковых запросов Mail.ru
Майл.ру обновил инструмент показывающий статистику поисковых запросов http://webmaster.mail.ru/querystat . Главная фишка сервиса — это распределение запросов по полу и возрасту.
Можно предположить, что сервис подбора слов Яндекса также учитывает запросы из Mail, т.к. в данный момент поисковая система Mail.ru показывает рекламу Яндекса, а сервис в основном рассчитан на рекламодателей. А раньше кстати, в Mail.ru показывалась реклама Google.
Кроме того, можно пользоваться такой хитростью. Примерное распределение аудитории между поисковиками такое: Яндекс — 60%, Гугл — 30%, Mail — 10%. Конечно, в зависимости от аудитории, соотношение может меняться. (Например, программисты могут отдавать предпочтение Google.)
Тогда можно посмотреть статистику в Яндекс и делить на 6. Получаем приблизительное количество поисковых запросов в Mail.ru
Кстати, точное распределение аудитории между поисковиками на Февраль 2014 года можно увидеть на скриншоте снизу:

Статистика запросов Rambler
Из графика выше уже можно заметить, что поисковая система Рамблер охватывает всего 1% аудитории интернета. Но тем не менее, у них есть свой сервис статистики ключевых слов. Он находится по адресу: http://adstat.rambler.ru/wrds/

Принцип такой же, как и в остальных сервисах.
Поисковой системой Бинг пользуется еще меньше наших соотечественников. А чтобы посмотреть статистику ключевых слов, придется зарегистрироваться как рекламодатель и разбираться в инструкциях на английском языке.
Сделать это можно по адресу bingads.microsoft.com, а статистику запросов можно будет посмотреть на этапе создания рекламной компании:

Статистика запросов Yahoo
В этой системе как и в предыдущей, вам нужно зарегистрироваться как рекламодатель. Смотреть статистику поисковых запросов надо здесь http://advertising.yahoo.com/
Как посмотреть поисковые запросы Youtube
Youtube тоже имеет свою статистику поисковых запросов, который называется «Инструмент подсказки ключевых слов». В основном он предназначен для рекламодателей, но ведь его можно использовать, чтобы прописывать у своего видео подходящие ключевые слова.
И выглядит примерно вот так:

Итог.
Мы рассмотрели все популярные системы подбора поисковых запросов. Надеюсь, этот обзор пригодится вам для написания статей, создания сайтов или настройки рекламы. Если у вас остались вопросы — задавайте их в комментариях.
Здравствуйте, уважаемые читатели блога сайт. Хочу еще раз коснуться темы подбора ключевых слов для отдельных статей и всего сайта в целом. Это позволит вам более прицельно попадать в ту аудиторию, которой может быть интересна ваша публикация.
Потенциально. Т.е. это не гарантирует успех, но позволяет на него надеяться. Другими словами, это необходимое условие для успешного развития сайта, но вовсе не достаточное.
Самым популярным инструментом, позволяющим анализировать статистику использования различных слов и фраз в запросах пользователей поисковых систем, является инструмент «Подбор слов» от Яндекса (знаменитый WordStat). Предназначен он для рекламодателей дающих объявления в , но это не суть важно, ибо выдаваемая им статистика может быть полезна и для оптимизации своего собственного сайта.
Работать с Вордстатом можно как вручную, так и с помощью специальных программ. Если нужно пробить одну-две ключевые фразы по статистике запросов Яндекса, то проще будет зайти на указанный чуть выше сайт, а вот если вы хотите набрать для себя базу ключевых слов по нужной вам тематике, то без автоматизации будет не обойтись.
Онлайн сервис «Подбор слов» от Яндекса
Я понимаю, что публикаций на тему составления семантического ядра в интернете более чем достаточно. Но, как мне кажется, они написаны в основном теми, кто занимается этим делом профессионально, т.е. оптимизаторами из SEO контор или фрилансерами. Описанные ими методы довольно-таки интересны, ибо позволяют автоматизировать и упростить процесс сборки ядра, но лично на меня они нагоняют скуку при чтении.
Описываемые ими мелочи и нюансы помогают сэкономить время при большом потоке проектов, которые проходят через их руки, но вот если у вас стоит задача подбора ключевых слов для своего собственного сайта , то в большинстве случаев излишняя автоматизация может даже помешать, ибо можно что-то упустить или не учесть.
Тут, как мне кажется, спешить не надо. Например, я когда-то купил на бонусы Профит Партнера замечательную программу Key Collector . Вот. Покрутил ее, повертел, да и отложил на дальнюю полку. Почему? Да просто она не для меня — сложна в освоении и понимании полезности всего имеющегося в ней богатейшего функционала. По той же причине я пользуюсь Яндекс Метрикой, а не Гугл Аналитиксом.
Конечно, я не прав и надо было упереться рогом и добиться понимания всех имеющихся в Key Collector фишечек (полезных безусловно). Но в реалии, я скачал с сайта того же разработчика облегченную версию этой программы по подбору слов, правда под непрезентабельным названием Slovoeb (написанное русскими буквами оно не очень-таки и печатно).
Все, теперь работаю исключительно с ним, а Кей Колектор у меня в очередной раз после обновления системы заблокировался (в нем имеется привязка к конфигурации компьютера) и мне лень опять списываться с автором, чтобы его реанимировать.
Поэтому сегодня буду говорить только про ручное использование инструмента «Подбор слов» от Яндекса, про использования Slovoeb в целях быстрого получения статистики по тысячам ключевых фраз разом и отсеивание пустышек. Есть и другие инструменты, подобные Вордстату (о них можно прочитать в статье про ), но они такой широкой популярности не снискали.
Вообще, конечно же, работа с Вордстатом до безобразия проста в плане теории, но достаточна муторна в плане практики. Кстати, не так давно у них поменялся дизайн, но не только. По субъективным ощущениям, скорость парсинга новой версии онлайн инструмента по подбору слов существенно увеличилась.
С чего начать? Со спокойного обдумывания сложившейся ситуации и того, что вы хотели бы получить в результате. У вас есть тематика вашего ресурса (будущего или уже имеющегося). Под эту тематику можете сходу подобрать десяток-другой фраз или слов, которые могут иметь к ней отношение. Как понять, какие именно из вертящихся у вас в голове фраз имеют перспективу?
Нужно посмотреть статистику их использования при обращении к поисковой системе Яндекс. Для этой цели и нужен Вордстат. Правда с недавних пор он доступен только для зарегистрированных пользователей, поэтому вам предварительно придется , а в нагрузку к нему еще и .
Если все это добро у вас уже есть, то не помешает вспомнить свои данные авторизации, ибо их придется вводить в Slovoeb для придания ему работоспособности. Дальше вводите ваш первый запрос в соответствующую форму на странице сервиса Подбор слов :

О, как много получилось. Вордстат выдает статистику по ключевым словам за последний календарный месяц. Значит за год можно будет получить число еще на порядок больше. Хотя это не совсем так. Одной из причин может являться колебание частотности запроса от времени года (т.е. сезонности).
Это можно проверить, переставив галочку в поле «История запросов» . Для наглядности возьмем, действительно, что-то с ярко выраженной сезонностью, где частотность ввода данного ключевого слова в поисковую строку Яндекса в зависимости от времени года может меняться в шесть раз.

Если интересующий вас запрос имеет региональную привязку, то это тоже существенно повлияет на частоту его ввода в Яндекс. Для того, чтобы это понять, достаточно кликнуть по ссылке «Все регионы» и выбрать нужную вам географическую привязку.
Например, вот так будет выглядеть статистика по аудитории Яндекса, которая интересуется доставкой пиццы в маленьком городе.

Кроме этого многие сеошники и владельцы сайтов проверяют ) по всевозможным ключевым словам, и не всегда для этого используют свои . А это значит, что происходит накрутка (не специальная) частотности. Поэтому не стоит безоглядно верить цифрам этой статистики и не стоит ее воспринимать буквально.
Да и без этого все не так просто. Будь это статистика исключительно по использованию одного только этого слова (словосочетания), которое вы ввели, то все было бы замечательно. Но сервис подбора слов Яндекса при вводе в него запроса без каких-либо дополнительных операторов учитывает в показанной цифирьке все фразы, в которых данное словосочетание использовалось (в любой словоформе).
Например, если вернуться к первому скриншоту, то можно с уверенностью сказать, что почти 900 000 раз за месяц пользователи яндекса вводили запросы, в которых встречалось слово Joomla (например, «шаблоны для Joomla» или «самые популярные в мире сайты на системе управления сайтами Joomla»).
Данная статистика поможет вам оценить перспективу создания сайта или отдельного раздела на данную тематику, но вот при написании конкретных статей нужно будет использовать уже другие цифирьки, обладающие большей конкретикой. Где их взять? Хороший вопрос, на который мы сейчас и постараемся ответить.
Как собрать статистику реальной частотности запросов (операторы Вордстата)
Прежде, чем приступать к практике, хочу остановиться на тех операторах Вордстата , которые можно использовать в сервисе подбора ключевых слов Яндекса. Собственно, их совсем немного. Думаю, что никто не сможет рассказать о них лучше, чем собственный хелп этого сервиса.

Лично я использую только два из них — кавычки и восклицательный знак. Вы вольны поступать так, как считаете нужным.
Итак, кавычки заставляют поисковую систему делиться статистикой по вводу только данной фразы. Однако, при этом будут учтены все возможные словоформы содержащихся в ней слов (падежи, числа). Например, так:


Странно, не правда ли? В три раза уменьшилась цифирька. А как же еще можно сформулировать данный запрос поисковой системе? Ну, если подумать, то скорее всего во множественном числе, тем более, что и оставшиеся цифирьки сразу видно куда подевались:

Ну вот, с теорией, считайте, покончили, пора приступать к практике. Все мои проекты носят информационный характер и поэтому сезонность и региональность запросов меня мало волнуют. Если у вас другая ситуация, то эти данные вам тоже придется учитывать, чтобы понимать перспективность.
Что нужно учесть при сборке семантического ядра сайта
Раз уж речь зашла о перспективности. Сборка состоит из нескольких этапов:

При разработке семантического ядра очень важно с чего-то начать (за что-то зацепиться). Несколько ключевых фраз почерпнутых у ваших конкурентов, взятых из головы или же очевидно напрашивающихся, станут вашей отправной точкой. Но обязательно продолжайте процесс поиска и всегда имейте под рукой бумажку, чтобы можно было записать возникшую идею и потом посмотреть статистику в сервисе подбора слов от Яндекса, чтобы убедиться в ее состоятельности.
Из любого высокочастотного запроса можно с помощью Вордстата или Slovoeb получить десятки или даже сотни ключевых слов для ваших будущих статей. Как это сделать? Для начала нужно найти такие высокочастотники. Это самые очевидные фразы, которые используют пользователи при обращении к Яндексу, когда хотят получить ответ на вопрос по той тематике, в которой вы хотите подвязаться на создание сайта.
Например, для моего блога это могут быть слова Joomla, WordPress, продвижение сайтов, раскрутка сайтов, заработок и т.д. С них можно начинать. Но так поступают многие, поэтому было бы не плохо, если все приходящие вам идеи будущих статей вы пытались бы оформить в те запросы, по которым их могли бы найти пользователи Яндекса. Надо попытаться думать, как рядовой пользователь интернета задающий вопрос поисковику.
Подбор слов для семядра непосредственно в Яндекс Вордстате
Ладно. Воду лить можно долго. Давайте наберем запрос «Продвижение сайтов» в Вордстате и посмотрим, что он нам с вами сумеет подобрать.

Замечательно. Мы получили кучу информации, которую теперь нужно будет попробовать как-то обработать. Яндекс нам подобрал слова на основе введенной нами фразы и распределил их по двух колонкам. Обе они очень важны.
В левой колонке Вордстата собраны все фразы, где непосредственно встречаются введенные ключевые слова. Справа от них отображается частотность их запроса у Яндекса его пользователями. Но не спешите радоваться, ибо частотность эта в большинстве случаев фейковая (). Т.е. написанные там цифры на самом деле могут быть фикцией.
Как же это проверить? Ну, первое что приходит в голову — открыть на новой вкладке браузера еще одно окно Вордстата и ввести в него все эти фразы из левой колонки по очереди, заключив их в кавычки.

Вот тогда вы получите реальную статистику (ну, или более близкую к реальной). Можно скопировать эти фразы в вордовский или экселовский документ и добавить высчитанные таким образом частотности.
Просто? Теоретически да, но на практике, после проверки десятка фраз из левой колонки (с приведенного скриншота) в Вордстате, открытом в новой вкладке, вы захотите на все это забить и пойти напиться (ну или повеситься).
Рутина, она не всем доставляет удовольствие. А ведь левая колонка окна сервиса «Подбор слов» еще и имеет постраничную навигацию. Представляете, там может быть до 50 страниц, что в сумме даст 2000 подобранных ключевых фраз. И все их вручную надо будет проверить, заключив в кавычки. Пожалуй, что такое под силу единицам.
И это еще не все. Мы же забыли про правую колонку Вордстата Яндекса . А ведь это просто-таки замечательная штука. Там отображаются запросы тех же пользователей, что вводили фразу из правой колонки, сделанные ими в ту же самую поисковую сессию. Это позволит вам существенно расширить семантическое ядро сайта и порой даже в очень неожиданном направлении.
Что со всем этим богатством из правой колонки делать? Просмотреть ее содержимое и все фразы, что имеют отношения к вашей тематике, а затем пробить их во вновь открытой вкладке браузера с Вордстатом. В нашем примере в глаза бросается словосочетание «оптимизация сайта» с высокой (потенциально) частотностью.

И что мы тут видим? А опять же много всего интересного. Из левой колонки нужно будет все фразы проверить на фейк с помощью заключения фразы в кавычки. А содержимое правой колонки можно проверить на нахождение там чего-то нового, чего вы еще не добавляли в свое семантическое ядро.
И так на протяжении многих часов можно сидеть с открытыми в разных вкладках браузера страницами сервис Яндекса «Подбор слов», чтобы ничего не упустить из потенциально возможных ключей и в то же время отсеять все пустышки. Через некоторое время, правда, вам захочется все это бросить, ибо усилия и усидчивость здесь нужны во истину не человеческие.
Вот именно на фоне подобных мучений ручного подбора ключевых слов и почувствуешь всю прелесть Key Collector, или его облегченной версии под названием Slovoeb. Какой же это кайф (без преувеличения) загнать в программу какой-нибудь пришедший вам в голову высокочастотный запрос, спарсить автоматически все страницы из левой колонки Вордстата, после чего также на автомате отсеять пустышки .
Полученный в результате список реально востребованных ключей можно будет отсортировать по убыванию частотности и сохранить в формате CSV для последующего анализа и разбивки по статьям. Кстати, процесс распределения ключевых слов по статьям можно тоже автоматизировать. Узнал об этом совершенно недавно из рассылки биржи ContentMonster (покупаю статьи последнее время в основном только у них).
Оказывается, что существует онлайн сервис KeyAssistant под эгидой этой биржи (он бесплатный, как я понял), который позволяет раскидать ключи по страницам, а страницы — по разделам. Объяснять его функционал довольно долго, поэтому предлагаю посмотреть «фильму» на тему и, возможно, оно вас заинтересует:
Ладно, это мы отвлеклись, а тем временем уже пора познакомиться с нашим сегодняшним героем с крайне непритязательным названием.
Как автоматизировать подбор слов из Яндекса в Slovoeb
Скачать Slovoeb можно по приведенной ссылке. Установки он не требует — достаточно распаковать скачанный архив и запустить файлик Slovoeb.exe
Сразу после запуска имеет смысл зайти в настройки программы, где на вкладках «Парсинг» — «Yandex Wordstat» в область «Настройки аккаунтов Yandex» нужно будет ввести хотя бы одну пару логин-пароль (разделенный двоеточием и без пробелов) для доступа к сервисам этой поисковой системы. Зачем? Я уже упоминал, что с недавних пор Вордстат позволяет собой пользоваться только авторизованным пользователям.

Обратите внимание, что аккаунты в Яндексе лучше будет создать новые (фейковые, т.е. не основные, где вы, например, работаете с РСЯ или деньгами). Почему? Парсить свою выдачу напрямую поисковик не разрешает (вместо этого предоставляет лимиты для работы XML выдачей), поэтому можно схватить бан аккаунта за проявление чрезмерной наглости.
Там же имеет смысл поставить максимальное количество страниц из левой колонки сервиса «Подбор слов» Яндекса, которое будет парситься (50). Это пригодится при пробивании ВЧ запросов, т.к. там может быть очень много возможных вариантов. Иногда даже на последней странице общая частотность равняется нескольким тысячам, что говорит о том, что не все ключи можно собрать с помощью Вордстата (к сожалению).
Если не хотите сильно нагружать и злить Яндекс, то на первой вкладке настроек «Общие» увеличьте диапазон таймаутов (перерывов между подачей запросов к поисковой системе).

Сохраняете настройки и жмете на кнопку «Создать проект», либо на «Открыть проект», если не закончили какую-то работу раньше.

Даете проекту название, после чего вводите в появившуюся строку интересую вам ключевую фразу или слово. Ввели? Хорошо, жмите на Энтер на клавиатуре.
Да, есть альтернативный вариант. Нажать на кнопочку «Левая колонка Yandex Wordstat» и ввести в открывшуюся форму сразу несколько фраз (по одной в строке), статистику по которым вы хотите спарсить. Потом жмете кнопку расположенную внизу и получаете за раз несколько списков слитых воедино.

В современной версии Slovoeb придется подождать пяток или чуть меньше минут, пока он состыкуется с Вордстатом (это происходит только после запуска программы, а в дальнейшей работе таких задержек не будет).
Потом начнется парсинг левой колонки сервиса «Подбор слов» по данной фразе на ту глубину (число страниц), которое вы установили в настройках. У меня там всегда 50 установлено. В итоге получите не более 2000 ключей включающих ваше исходное словосочетание.

Для примера я взял супер ВЧ запрос «работа». Как видите, даже на последней странице Вордстата общая частотность фраз зашкаливает за десять тысяч. Следовательно, мы в этом случае не можем с помощью данного инструмента охватить весь пул запросов и многое остается за кадром. Вытащить «хвост» тоже, наверное, можно, но это уже гораздо сложнее и менее надежно.
Так, это мы просто спарсили ключи, но ведь нужно еще отделить зерна от плевел, т.е. понять, какие из этих ключевых слов имеет смысл дальше использовать в семантическом ядре, а какие отбросить в силу их крайне низкой реальной частотности . Последняя вычисляется благодаря заключению фразы в кавычки или еще с добавлением восклицательных знаков.
В Slovoeb для этого нужно будет всего лишь выбрать из выпадающего меню кнопки «Частотности Yandex.Wordstat» последний или предпоследний пункты. Разницу между ними вы уже должны понимать, поэтому выбирайте то, что считаете нужным. Я почему-то предпочитаю последний вариант, но это, возможно, излишне ограничивает результаты.
Пробивка реальной частотности в Slovoeb идет гораздо медленнее парсинга и что важно, не заходите в этом время в Вордстат через браузер, ибо , на которой данная программа у меня зависает. Возможно, что это проблема имеет место быть только на моем компьютере, но все же стоит предупредить.
За процессом проверки реальной частотности вы можете следить воочию — в соответствующей колонке в реальном времени будут появляться новые цифры. Хотя имеет смысл это дело пустить на самотек и пойти заняться чем-то более полезным, а в программу можно лишь периодически заглядывать. По окончании процесса сбора красный шестиугольник в верхнем левом углу станет серым.

При желании вы сами можете остановить процесс, выбрав соответствующий пункт из контекстного меню этой кнопки. Проект можно будет сохранить, а Slovoeb закрыть. А потом опять открыть программу и сохраненный проект, после чего описанным выше способом продолжить сбор статистики. Очень удобно и, главное, просто до безобразия.
Вот. После окончания процесса вы можете отсортировать результаты по убыванию частотности, кликнув по заголовку столбца со статистикой фраз заключенных в кавычки, или с ними и восклицательными знаками перед каждым словом. Получится очень наглядно, ибо самые перспективные (пусть зачастую и не реальные в силу высокой конкуренции) запросы будут находиться вверху списка.

Советую сохранять все полученные в результате подбора ключевых слов списки в файл. Делается это в Slovoeb с помощью показанной на скриншоте иконки, расположенной в верхней части окна программы. Сохранение идет в формате CSV, который при желании можно открыть и обычным Экселем, главное указать правильный разделитель столбцов, чтобы все срослось.
Если не получается, то в настройках программы на вкладке «Интерфейс» — «Экспорт» выберете другой формат сохранения (xlsx). Там же можно посмотреть и разделитель используемый при экспорте в CSV.

Лишние столбцы в Экселе можно удалить (либо убрать в тех же самых настройках экспорта простым удалением галочек с не нужных вам столбцов — см. приведенный чуть выше скриншот), дабы они не снижали наглядность. Лично я оставляю только саму ключевую фразу и ее реальную частотность, а все остальное — в топку.

Собственно, с этими списками уже можно работать, что-то беря оттуда напрямую, а что-то опять пробивая через Вордстат на предмет получения новых ключей (например, не полную фразу, а встретившееся в ней слово или словосочетание, которое само по себе может породить массу вариантов). В общем, процесс весьма творческий и в силу его сильной автоматизации не шибко утомительный, особенно в сравнении с описанным выше ручным методом использования сервиса «Подбор слов».
Другие возможности Slovoeb по сбору статистики
Да, забыл еще упомянуть, что Slovoeb умеет собирать и поисковые подсказки . Это то, что выпадает при вводе запроса в поисковую строку Яндекса или Гугла.

Среди них тоже могут содержаться вполне себе интересные варианты ключевиков, которые потом можно будет проверить описанным чуть выше способом на предмет реальной их частотности.
Раньше для этого существовала отдельная утилита (СловоДер) от того же разработчика (Александра Люстика), а сейчас этот функционал заключен в одной программе. Для сбора поисковых подсказок достаточно нажать соответствующую кнопку на панели инструментов Slovoeb.
В открывшемся окне нужно поставить галочки напротив тех поисковиков, откуда эти подсказки будут дергаться.

Собственно, следует также указать ключевые слова, для которых эти подсказки будут собираться и нажать кнопку «Начать сбор». Собранные ключи из подсказок добавятся к общему списку, чтобы потом можно было их все скопом проверить и собрать статистику частоты использования.
В общем списке они будут помечаться другим значком, чтобы вам было нагляднее с ними работать и различать парсинг Вордстата и поисковых подсказок.

Тоже самое касается и сбора слов из правой колонки Вордстата (Slovoeb умеет ее парсить тоже).

Чуть выше по тексту я говорил, что очень важно при сборке семантического ядра обращать внимание не только на частотность подобранных слов и фраз, но и на то, насколько высокая конкуренция существует в выдаче Яндекса и Гугла по данным запросам. Чем она выше, тем сложнее вам будет пробиться в ТОП.
Для ее оценки многие предлагают использовать число ответов поисковых систем, которые они дают на данный запрос. Чуть выше я писал об этом подробнее. Так вот, наша замечательная программа умеет парсить это самое число ответов из выдач Яндекса и Гугла.
Т.е. по всем собранным словам вы сможете пробить их конкурентность с помощью кнопочки KEI на панели инструментов Slovoeb:

Параметр KEI получается и, чтобы на него опираться, лучше будет воспользоваться Key Collector (платная версия данной бесплатной программы с существенно более расширенным функционалом).
Как вы можете видеть, даже у упрощенной версии программы имеется довольно-таки богатый функционал. Что уж говорить о Key Collector. Другое дело — нужен ли вам этот функционал? Лично мне оказалось очень трудно выкроить время на его освоение, тем более, что я не видел в этом особых перспектив. Я не прав? Разубедите меня в комментариях тогда.
Тем не менее, не у всех есть время и силы на проведения подобной работы (сбор полного семядра), но делать ее все равно нужно обязательно . Однако, если есть спрос, то будет и предложение. Всегда найдутся люди, которые готовы будут проделать это за вас, другое дело, что они могут оказаться не всегда честными и исполнительными.
Позволю себе наглость и приведу в завершении видео, взятое с блога Максима Довженко , где он рассказывает про настройки и подбор слов в Slovoeb:
Если статистика ключевых запросов применяется как простой подбор слов , тем самым используя несовершенство поисковиков для рекламных и маркетинговых ходов, то подобная деятельность называется «Черная оптимизация».
Белая оптимизация в отличие от «черной», служит рабочим инструментом редакторов сайтов, вебмастеров и оптимизаторов. сайта нужна для увеличения посещаемости и удовлетворения потребности в информации. Для рутинной работы по сбору и структурированному изменению информации используют парсинг ресурсов.
Незаменимым источником информации для ученых – лингвистов оказалась статистика запросов поиска. Исследовав строку поиска , таких как « », или на сайтах знакомств, языковеды могут провести такие исследования, которые невозможно осуществить другим способом, проверить самые смелые свои гипотезы.
Органы государственного управления особенно заинтересованы в данных, которые отображает статистика запросов в поисковых системах. Однако, анализ данных информационных систем, можно использовать не только как на улучшение жизни людей, но и для установления тотального контроля.
 Используемая в РФ статистика запросов ОКПО, в Росреестр или количество выписок из ЕГРИП применяют для защиты от мошенничества, проверки на соответствие прав собственников, учета для налоговой инспекции. Сравнение с данными за прошлый период позволяет оценивать их деятельность.
Используемая в РФ статистика запросов ОКПО, в Росреестр или количество выписок из ЕГРИП применяют для защиты от мошенничества, проверки на соответствие прав собственников, учета для налоговой инспекции. Сравнение с данными за прошлый период позволяет оценивать их деятельность.
Яркий пример попытки установить слежку за гражданами показали власти США. Обязав через суд America Online, MSN, Yahoo и Google предоставлять статистические материалы, они прикрылись желанием помешать распространению порнографии. Однако статистика запросов Гугл осталась недоступна чиновникам. Компания отказалась предоставлять информацию даже по решению суда.
Статистика запросов пользователей выделяет четыре вида ключевых слов:
- длинный хвост;
- низкочастотные;
- среднечастотные;
- высокочастотные.

Если какой-либо вопрос пользователи вводят очень редко, то он расценивается как «Длинный хвост». Например, такой: «Купить фанеру в Омске оптом». Хотя и показываются «хвосты» редко, их нельзя игнорировать в работе над ключевыми словами:
- По long tail у них отсутствуют конкуренты.
- Такие ключевики используют самые нужные посетители, они чаще настроены на покупку.
- Через такие запросы на сайты заходят до 90% всех посетителей.
К низкочастотным ключам можно отнести низкоконкурентные и нечасто запрашиваемые фразы. Например, такую: «Куплю квартиру в Одессе дешево». Отличие от «длинного хвоста» в более частом показе за год. Случается, что такие запросы хорошо срабатывают в коммерческих нишах при высокой конкуренции.
Что такое высокочастотные ключи ясно из названия – запрашиваемые максимально большое количество раз. Выглядят такие Топ запросы так: «Ютуб» или « ». Вроде бы такие ключи должны привлекать множество посетителей, но именно здесь кроется опасность для новичков. Принцип высокочастотной ловушки:
- высокий уровень конкуренции при низком трасте;
- низкая конверсия с большим показателем отказа страницы;
Один из самых популярных сервисов Рунета – Yandex. В 1998 году было начато изучение русскоязычного интернета по месяцам с исследования «НИНИ-индекс». Сегодня статистика ключевых запросов Яндекс доступна всем. Как узнать статистику запросов в Яндексе? Этой цели служит система по продаже контекстной рекламы Яндекс Директ.
 Статистика поисковых запросов Яндекс имеет специализированный сервис wordstat.yandex.ru. Однако он позволяет узнать частотность запросов только в Яндекс Директе. Для подавляющего людей, которых интересует статистика запросов – этого хватает.
Статистика поисковых запросов Яндекс имеет специализированный сервис wordstat.yandex.ru. Однако он позволяет узнать частотность запросов только в Яндекс Директе. Для подавляющего людей, которых интересует статистика запросов – этого хватает.
Главная страница Яндекс Вордстат имеет поисковую строку для ввода слова или фразы. Статистика поисковых запросов Яндекс не зависит от того, в единственном или множественном числе написана фраза. Словоформы и предлоги Яндекс не учитывает. Если написать слово в кавычках или с восклицательным знаком впереди, то можно узнать именно его частотность. Существуют и другие операторы для более точной работы сервиса. Яндекс Вордстат позволяет узнать:
- прогноз фраз на месяц;
- поисковые запросы по сезонам года, расположенные по алфавиту;
- какие темы популярны у информационных сайтов за определенный период;
- насколько популярна фраза в заданном регионе или по городам .
Статистика ключевых запросов Гугл также доступна для изучения. Находится статистика поисковых запросов Google по адресу adwords.google.com. Крупнейшая поисковая система в мире предоставляет сведения в формате csv, т. е. предназначенном для передачи данных таблиц. Для зрительности гугл адвордс выводит на дисплей их график. Отчеты, которые выдает статистика запросов Google AdWords, очень подробные. В них отражается:
- обычная статистика;
- конкуренция на конкретный запрос;
- история трафика по словам;
- подсказка минус-слов (слов для отсеивания нецелевого трафика);
- реальная стоимость некоторых ключей.
 В технологичной платформе допускается тонкая настройка таргетинга, бюджетирования и других параметров рекламных компаний. Таргетинг (механизм для выделения целевой ) разрешает некоторым странам Азии и Восточной Европы (Россия, Украина, Беларусь) пользоваться удлиненными текстовыми объявлениями (30 символов – заголовок, 38 – вторая и третья строки).
В технологичной платформе допускается тонкая настройка таргетинга, бюджетирования и других параметров рекламных компаний. Таргетинг (механизм для выделения целевой ) разрешает некоторым странам Азии и Восточной Европы (Россия, Украина, Беларусь) пользоваться удлиненными текстовыми объявлениями (30 символов – заголовок, 38 – вторая и третья строки).
Посмотреть статистику запросов в другом виде можно на графиках Google Trends. Вводя до пяти различных фраз, можно графически в натуральных числах сравнить мировой интерес к ним за два года. Данные из Google Trends прослеживают даже показатели заболевания гриппом. Реальная статистика запросов определенной тематики связана с процентным отношением посещения врачебных кабинетов.
Хотелось бы обратить внимание читателей при анализе веб-данных для бизнеса на еще один инструмент – Google Analytics. Услуги от Гугл Аналитикс предоставляются бесплатно. Система позволяет :
- Получать сведения о посетителях сайта с классификацией по возрасту, странам, полу, языку и интересам за последние полчаса.
- Проверить, откуда пришли посетители .
- Отслеживать события на сайте . Сюда относится – время, затраченное на посещение ресурса, сколько и какие страницы вызвали интерес, показатель отказов.
- Взаимодействовать с разными службами и приложениями Google из .

Анализ других поисковых систем
Статистика запросов Рамблер (Rambler) потеряла свою актуальность. Сегодня желающие могут использовать яндексовский WordStat.
Статистика запросов mail ru незаменима для тех, кто занимается таргетированной (воздействующей на конкретные группы потребителей) . Статистика запросов майл ру позволяет распределять их по возрасту и половому признаку. Однако здесь отсутствует возможность распределения по географическому принципу и имеется ограничение по количеству запросов.
Статистика поисковых запросов mail ru имеет много возможностей для обработки данных. Для этого она использует собственные проекты. , в Одноклассниках и Моем мире сильно облегчает выполнение задачи.
Mail.ru Group создала для москвичей конкурента Авито – онлайн-классифайд «Юла». Он уже подключен к рынку в Москве. Новостройка или старого фонда доступна для фотографирования в приложении. Подготовка к продаже и сопровождение сделок входит в перечень оказываемых услуг.
 Статистика поисковых запросов ВКонтакте пользователям недоступна. Она отдельно не ведется. Для пытающихся вести продажи на сайте или организовать коучинг, доступна только внутренняя статистика запросов ВК. Имеются в виду
сведения о посещении и подписке. Анализ подобных данных позволяет спрогнозировать отдачу от размещенной рекламы.
Статистика поисковых запросов ВКонтакте пользователям недоступна. Она отдельно не ведется. Для пытающихся вести продажи на сайте или организовать коучинг, доступна только внутренняя статистика запросов ВК. Имеются в виду
сведения о посещении и подписке. Анализ подобных данных позволяет спрогнозировать отдачу от размещенной рекламы.
Компания Microsoft устанавливает в каждый компьютер Internet Explorer. Поисковой системой в браузере по умолчанию служит Бинг (Bing). В ней создан альтернативный AdWords сервис Bing Ads. С его помощью можно управлять сразу несколькими рекламными компаниями. Для этого необязательно быть онлайн. Объявления, созданные в Bing Ads, отображаются в системе Bing и Yahoo.
Статистика запросов Yahoo требует регистрации в качестве рекламодателя. Адрес, по которому нужно искать статистику поисковых запросов – advertising.yahoo.com. Все инструкции на английском языке, что несколько затрудняет работу для русскоязычного .
Статистика запросов YouTube раньше отображалась на сервисе «Инструмент подсказки ключевых слов». С 2015 года статистика запросов Ютуб заменена планировщиком Display Planner рекламной службы AdWords. Тех, кто развивает свой бизнес на YouTube, обычно интересует количество людей оформивших подписку и отказавшихся от нее.
2016 год показал рост популярности сайта Авито. Статистика запросов на Авито ежедневно фиксирует размещение более 1 млн. объявлений. Товары на сайте распределяются по категориям. демонстрирует более 35 млн. посещений в месяц.
Запросов на регистрацию становится все больше. Точные цифры по просмотрам можно узнать в правом верхнем углу объявления. Желающие получить дополнительные сведения отправляются на платный pro-аккаунт.
Яндекс Маркет можно назвать рекордным по посещаемости прайс-агрегатором (ресурсом, специализирующимся на сборе данных о продукции в интернет-магазинах). До 2016 года ресурс обслуживался Яндексом, а позже стал самостоятельным юридическим лицом. Преимущества сервиса:
- возможность привлечения клиентов благодаря солидной аудитории;
- проверка магазинов модераторами;
- окупаемость затрат при наличии качественного товара.

Для получения дополнительного поискового трафика крупные магазины используют поиск по тегам и хэштегам. Пример: тег «Синие носки». На странице появляются все, что подходит под такое название. Кроме этого становятся доступны советы по уходу или разные расцветки.
Статистика запросов Маркет доступна для конкретного товара, если указан идентификатор из прайс-листа. Фильтрация товарных предложений – еще одна удобная опция Яндекс Маркета. Статистика запросов по предложениям доступна только за 30 дней.
Для замены специалиста по продвижению создан сервис PriceLabs. Он позволяет делать автоматическое размещение на Маркете, отслеживать цены конкурентов, анализировать эффективность рекламной кампании.
Отображает количество подписок и отписок за какой-то период. Также учитываются лайки и комментарии. Статистика поисковых запросов в Инстаграм доступна:
- В бизнес-аккаунте на « »;
- В приложениях Iconosquare, Statigram.
- На телефоне в приложении FollowMe.
На Международной торговой площадке Etsy по продаже изделий ручной работы нет возможности посмотреть статистические данные. Статистика запросов на Еtsy определяется при помощи сторонних ресурсов, например, Google AdWords.
Amazon.com – крупнейший в мире американский интернет-магазин. Статистика запросов требуется крупным рекламодателям из-за количества людей пользующихся услугами компании.
Самой востребованной в Китае стала поисковая система Baidu. Чтобы освоить азиатский рынок желательно создать сайт с оптимизацией под Baidu. Статистика запросов Байду представлена собственной web-аналитикой (бесплатная и платная версия). Подбор keywords возможен как онлайн, так и оффлайновой программой.
 Для интернет-аукциона eBay создан интересный инструмент watchcount.com. Watchcaunt показывает, каким товаром преимущественно интересуются покупатели. Проверка отдельного слова или целого раздела также доступна в Watchcaunt.
Для интернет-аукциона eBay создан интересный инструмент watchcount.com. Watchcaunt показывает, каким товаром преимущественно интересуются покупатели. Проверка отдельного слова или целого раздела также доступна в Watchcaunt.
Заключение
Для каждого крайне важна кластеризация запросов семантического ядра. Применение ключевых слов, которые используют поисковые системы, требуется для качественной раскрутки любого сайта. Статистика запросов позволяет в цифрах оценивать частоту посещений по фразам. Анализ данных делает более понятным механизм собственной продукции.
Яндекс.Wordstat (https://wordstat.yandex.ru/) – это очень полезный и бесплатный (!) сервис Яндекса, созданный для того, чтобы подбирать ключевые слова для , а также делать много других крутых вещей. Этот сервис в целом очень помогает в . В этой статье мы разберемся, как пользоваться Вордстатом и проанонсируем, что можно сделать с полученными с помощью этого сервиса данными.
Многие ошибочно полагают, что Yandex Wordstat нужен только лишь для того, и впоследствии использовать полученные наиболее популярные запросы , которые будут размещены на сайте. Но это неверно: Вордстат - многофункциональный инструмент , несмотря на всю свою простоту. Например, с помощью него можно составлять структуру как отдельных страниц, так и самого сайта в целом.
Как пользоваться Яндекс Вордстатом?
Проще простого! Пользоваться этим инструментом настолько легко, что с этим справится даже новичок. К тому же Вордстат отлично работает на современных мобильных устройствах. Все необходимые действия займут у вас не более минуты. Чтобы начать работу в этом сервисе, выполните следующие действия:
- Войти в почту на Яндексе;
- Перейти по ссылке https://wordstat.yandex.ru/;
- Вбить в строку нужное слово или словосочетание и нажать кнопку «Подобрать» (справа).
Для начала убедитесь, что у вас есть зарегистрированный аккаунт электронной почты на Яндексе. Если такого у вас нет, это не повод искать другие сервисы: регистрация «яндексовского» почтового аккаунта займет всего лишь несколько минут. В правом верхнем углу экрана кликните по кнопке «Почта» и далее следуйте инструкции, заполняя поля в предложенной анкете.
Заходим в свой новый или же старый аккаунт и переходим по ссылке https://wordstat.yandex.ru/. Если вы умудрились забыть этот адрес, можно просто вбить в поисковую строку «вордстат» на русском и перейти по первой ссылке - не ошибетесь.
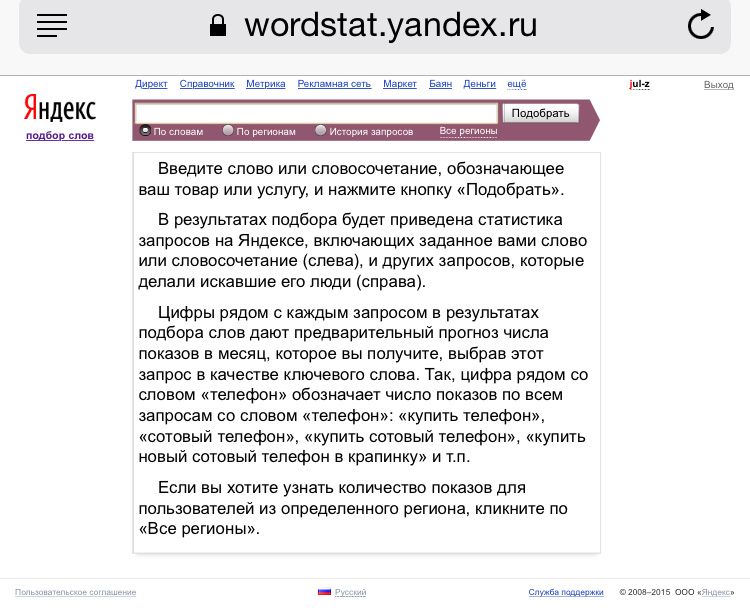
Так изначально выглядит Яндекс.Wordstat.
Вбиваем необходимое слово или словосочетание в строку, нажимаем «Подобрать» и уже через пару секунд получаем результат. Вордстат - очень удобный сервис, поскольку он осуществляет подбор ключевых слов в разных падежах и числах , а также умеет разбивать их на отдельные слова. Поэтому в строку достаточно вбить словосочетание в именительном падеже. Например, набрав «популярные запросы» мы получаем и «поиск популярнЫХ запросОВ», и «популярные ПОИСКОВЫЕ запросы».

В выдаче окончания слов могут быть различными, а искомое словосочетание могут разбивать другие слова.
Сверху изначально открыта вкладка «Все», которую можно переключить на «Только мобильные». Из названия кнопки ясно, что во втором случае мы увидим запросы, собранные Яндексом исключительно из трафика с мобильных устройств (телефонов, смартфонов, планшетов и так далее).
Вспомогательные символы, уточняющие ваш запрос
Как и в поисковых системах, в Вордстате можно использовать синтаксис для уточнения вашего запроса. В таблице ниже наглядно продемонстрированы основные символы и их значения, где ххх и ууу — это любые слова.
Знак минус («— «) перед каким-либо словом означает убрать из полученного списка все словосочетания, где оно содержится. Например, вбив в Вордстат «популярные запросы -слова «, отминусуем словосочетания вроде «популярные слова запроса», «популярные слова в запросах» и другие.
Знак плюс («+ «) перед словом означает обязательное его присутствие в выдаваемых запросах. Это касается предлогов и союзов, так как в обычном режиме Вордстат «съедает» многие служебные части речи, то есть полностью игнорирует их. Если точнее, то сервис НЕ замечает короткие союзы и предлоги («и», «к»…), в то время как более длинные все же достойны его внимания («перед», «также»…). Например, если мы вбиваем в строку фразу «популярные запросы в яндексе», то в списке среди прочих запросов находим и «популярные поисковые запросы яндекс», и «топ популярных запросов яндекс», и другие словосочетания без предлога «в». А если мы вобьем «популярные запросы +в яндексе», то получим лишь то, что искали, без лишнего «мусора».
Знак кавычки («» ) позволяет увидеть выдачу только с теми словами, которые написаны внутри (закавычены). Обратите внимание, что их порядок и окончания могут быть разными.
Восклицательный знак («! «) перед словом обозначает, что в выдаче мы получим точное вхождение слова (в нужном нам числе и падеже).
Сортировка по регионам
Также Вордстат позволяет делать сортировку по регионам. Для этого находим справа под строкой кнопку «Все регионы» и в появившемся окошке проставляем необходимые нам галочки. Кстати, в этом же окне справа вы найдете очень удобную опцию «Быстрый выбор». С помощью нее вы можете быстро (в один клик) обозначить для подбора слов один из четырех наиболее распространенных географических вариантов: Москва и область; Санкт-Петербург и область; Украина; Россия, СНГ и Грузия.
Как перейти к низкочастотным запросам?
Снизу (после полученного списка) вы сразу увидите переход на следующую страницу. К сожалению, перейти в самый конец выдачи сервиса с помощью одного нажатия не получится, так как отлистывать можно лишь по одной странице. Напротив высветившихся запросов Вордстат показывает их количество и собирает все словосочетания, они же , которые искали минимум 5 раз за последний месяц. Внимание: если листать страницы слишком быстро, а также при долгом пребывании на сервисе может появиться капча . Если Яндекс заставляет вас ввести указанный на картинке буквенно-цифровой код, то он просто хочет убедиться, что вы не робот, а живой человек.
В Вордстате можно листать только на одну страницу вперед. Чтобы перейти на десятую страницу, придется нажать на кнопку «Далее» девять раз.
Если для дальнейшей работы с популярными запросами вам нужно вставить полученную статистику в Excel, нажмите Ctrl+C, выделив мышкой все необходимые данные в браузере, а затем в Экселе нажмите правую кнопку и укажите «Вставить как» => «Текст без форматирования». Так ваша таблица будет выглядеть красиво и аккуратно.
Что делать с очень популярными запросами?
При использовании Вордстата есть одно «но», актуальное лишь для суперпопулярных запросов: данный сервис никогда не показывает данные, расположенные дальше 40-й страницы полученных словосочетаний. Например, если вбить в строку фразу «скачать фильм», мы получим огромное количество запросов: почти пять миллионов! Очевидно, что в этом случае на сороковой странице конец выдачи мы не увидим.

«Скачать фильм» — это очень популярный запрос. Даже СУПЕРпопулярный.
Но выход, опять же, есть. Если у вас появится необходимость «заглянуть» дальше, вы можете использовать одно из сторонних решений для Вордстата (такой инструмент называется парсер ). Их довольно много, поэтому мы назовем самые известные: Key Collector, YandexKeyParser, Yandex Wordstat Helper (« Хелпер» ) и Yandex Wordstat Assistant («Ассистент») . О том, как пользоваться подобными инструментами, а также о том, как именно составлять структуру сайта, используя наиболее популярные запросы, мы напишем в следующих статьях.
Получив список искомых запросов, справа мы видим столбик под названием «Запросы, похожие на «ххх»» (ххх — вбитое нами словосочетание). Вордстат автоматически подбирает словосочетания, которые также могут быть интересны и полезны пользователю. Принцип их отбора следующий: сервис показывает нам слова, которые люди в Яндексе искали вместе с набранным нами запросом. Иначе говоря, из Вордстата мы можем узнать, как люди пытаются решить свои проблемы (или удовлетворить свои потребности) в Интернете.
Кликнув на одно из словосочетаний, мы увидим, что выбранный запрос переместился в строку, то есть мы сразу получили новую выдачу по новому запросу. Нельзя говорить о том, что данная опция будет полезна всем и всегда, так как, например, вбив слово «котики» в строку, в столбце справа мы увидим довольно странные словосочетания. Вряд ли кто-то поспорит с тем, что «вопросы в одноклассники» и «отгадайка ответы» имеют довольно косвенное отношение к котикам. 🙂 Но это только на первый взгляд, ведь люди искали именно такие фразы, а значит, для статистики это может быть очень важно. Так что эта функция может быть очень полезна, например, для расширения запросов тематики.
Что еще можно посмотреть в Вордстате?
Обратите внимание, что под строкой слева есть 3 опции выдачи Вордстата: «По словам» , «По регионам» и «История запросов» .Последняя функция позволяет определить сезонность запросов. Там вы можете увидеть графики по месяцам или по неделям и с их помощью отследить тренды за последний год. По умолчанию сервис установлен на функцию «По словам», так как она считается наиболее популярной. Ее мы подробно разбираем сейчас, а две другие возможности Вордстата мы рассмотрим чуть позже.
Что нужно обязательно запомнить о сервисе Яндекс Вордстат?
- Этот инструмент абсолютно бесплатный;
- Чтобы им воспользоваться, нужно быть обязательно зарегистрированным в Яндексе;
- С помощью Вордстата можно подбирать ключевые слова для текстов;
- Выдача популярных запросов на многие тематики будет сильно отличаться каждый месяц или в зависимости от сезона (например, если вы введете запрос «новости» или «куда пойти», то будете все время получать разный список);
- Вордстат не ограничивается разделом «По словам».
Изучайте запросы аудитории и , а Yandex Wordstat окажет вам помощь в этом нелегком деле. Удачи!
Здравствуйте, уважаемые читатели! Сегодня речь пойдет о популярном сервисе, который знают практически все блоггеры, веб-мастера и многие интернет-маркетологи. В этой статье Вы узнаете, как эффективно пользоваться статистикой Яндекс Вордстат (Подбор Слов) с целью успешного seo-продвижения своих сайтов. Пост познакомит Вас с возможностями данного сервиса, покажет его интерфейс, раскроет секреты операторов для парсинга запросов.
Знакомство с сервисом Yandex Wordstat
Предназначение сервиса
Поисковая система Яндекс является одним из двух гигантов в Рунете, который дает различную информацию практически на любой вопрос своих пользователей. Знание этих вопросов (поисковых запросов) дает много важной и полезной информации для успешной реализации следующих задач:
- анализ запросов для создания структуры веб-ресурса;
- поиск ключевых слов для ;
- анализ популярности тематики в интернет-маркетинге;
- поиск запросов для рекламной компании в Яндекс Директе.
Благодаря статистике поисковых фраз Вордстата, любой блоггер и вебмастер может получить исчерпывающую информацию для решение вышеперечисленных задач. Именно поэтому Wordstat является одним из самых популярных сервисов в сети. Куда уж без него… 🙂
Особенности Вордстата
Регистрация. Сейчас без регистрации никуда — любой нормальный сервис или онлайн-инструмент требует внесения персональных данных. «Подбор Слов» не исключение — для его использования требуется настоящий аккаунт в поисковике Яндекс.
Блокировка. Есть такая неприятная вещь — при неправильной работе с сервисом, Яндекс может заблокировать аккаунт пользователя. Это случается в двух случаях:
- при нарушении «Лицензии на использование поисковой системы»;
- при заражении Вашего компьютера вирусом;
Первый случай понятен — что-то делаем в разрез правил — получаем бан. Второй же вариант событий происходит из-за того, что появившийся вирус на нашем компьютере создает огромную нагрузку на сервис.
Кстати, таким же «вирусом» может быть одна из программ для сбора семантики — или . Каждая из них по требованию пользователя может парсить огромное число поисковых запросов в Яндекс Вордстате. Что при неправильном подходе может дать колоссальную нагрузку на сервис.
Капча. Это такая картинка (как правило — с цифрами), которая блокирует дальнейшую работу с Вордстатом. Она может появиться в следующих случаях:
- если в нашем браузере закрыты куки (файлы с данными сайтов, которые мы посещяли);
- если в нашем браузере отключены альтернативные куки (Flash);
- если в нашем браузере отключена поддержка языка JavaScript;
- если по определению IP компьютера мы не в зоне СНГ.
Для решения последней проблемы есть отличный вариант (его подсказал постоянный читатель моего блога, Руслан Цвиркун) — расширение friGate для браузера.
Возможности Подбора Слов
Статистика Вордстат — это не только просто большой склад поисковых запросов. С помощью этого сервиса можно узнать:
- примерный прогноз выбранных фраз на месяц;
- сезонность поисковых запросов в течение года;
- популярность тематик для информационных сайтов;
- оценку популярности фразы в конкретном регионе.
Все эти возможности тем или образом могут пересекаться. Особенно это часто возникает при формировании стратегии раскрутки коммерческих сайтов. Для информационных проектов важно увидеть в статистике запросов популярность тематик. Также это важно, когда нам нужно создать новый сайт, но есть вопросы по выбору популярной темы ресурса.
Интерфейс сервиса «Подбор Слов»
Основная задача интерфейса сервиса Вордстат — дать общее представление пользователю об интересующих его поисковых запросах. Конечно, для решения различных seo-задач приходиться этим сервисом заниматься вплотную. Поэтому интерфейс достаточно прост и понятен.
К сожалению, при частой и затяжной работе с ним понимаешь, как он неудобен. Поэтому для больших задач используются более мощные инструменты, такие как , Топвизор и др.
Рассмотрим рабочий экран сервиса, а также интерфейс всех его инструментов.
Инструмент «По словам» (главный экран)
На следующем рисунке показан интерфейс главного экрана сервиса Yandex Wordstat (он же инструмент «По словам»):

Вот перечень основных элементов, показанных на рисунке:
- Поле ввода поискового запроса (1) . В этом поле мы отображаем фразу, по которой хотим узнать данные из Яндекса (популярность запроса, перечень словосочетаний с этой фразой, возможная выборка с помощью различных операторов).
- Кнопка инструмента «По словам» (2). Определяет список фраз в инструменте «По словам» в зависимости от указанных операторов Вордстата. Окно инструмента открывается по умолчанию при первом заходе на статистику, используется чаще всего.
- Кнопка инструмента «По регионам» (3). При нажатии этой кнопки переходим в раздел, который покажет региональную популярность анализируемого запроса.
- Кнопка инструмента «История запросов» (4). Открывает экран, дающий информацию популярности выбранного запроса за последние 2 года.
- Кнопка «Все регионы» (5). Позволяет выбрать регион, для которого собирается статистика по выбранному запросу.
- Дата последнего обновления статистики (6). Показывает число, когда была дополнена база данных поисковых запросов Яндекса.
- Левая колонка Вордстата (7). Дает перечень фраз с частотностями, в которых содержится указанный в поле ввода (1) поисковый запрос.
- Правая колонка Вордстата (8). Показывает перечень других поисковых запросов, которые набирали пользователи Яндекса, искавшие начальную фразу (1).
- Переход на статистику по мобильным запросам (7). Показывает статистику Вордстата по искомой фразе, которую набирали на мобильных устройствах.
Теперь рассмотрим интерфейс и принцип работы каждого инструмента в отдельности. Узнаем, какое у них предназначение в сервисе, увидим данные статистики.
Левая колонка сервиса
Задав свою фразу в поле ввода, в левой колонке мы получаем перечень поисковых запросов Яндекса, которые включают в себя нашу фразу. То есть, мы видим список поисковых словосочетаний, которые наряду с другими словами включают нашу первоначальную фразу.
Цифра рядом с каждым запросом левой колонки дает предварительный прогноз числа показов за месяц. Это число показов по всем запросам, в которую входит каждый запрос. Например:

Кстати, эти цифры напротив каждого запроса берутся с данных поисковой базы данных Яндекса за последние 30 дней до даты обновления статистики.
Именно поэтому числа показов на первой и второй картинках по одному и тому же запросу отличаются («внутренняя перелинковка» — 1630 и 1647) — различие получилась по случаю разных дат обновления. На каждом из изображений указаны свои даты — 22 и 24 сентября.
И еще важное замечание — число показов будет отличаться при указании различных регионов продвижения. Указывается регион с помощью ссылки, которая находится под кнопкой «Подобрать». Ее анкор при первом заходе в статистику будет иметь текст «Все регионы». Если мы выберем какой-нибудь регион, то в дальнейшем текст анкора будет соответствовать указанному месту.

Правая колонка статистики
В правой колонке севрис «Подбор Слов» показывает поисковые запросы, которые набирали именно те пользователи Яндекса, которые искали нужную нам фразу. То есть за одну сессию работы с поиском Яндекса каждый пользователь, наряду с нужной нам фразой (которую мы смотрим в статистике Вордстат), набирал другие словосочетания.
Эти все, так скажем, смежные запросы накапливались за месяц. И затем, когда пользователь Яндекса набирал искомую фразу, все смежные месячные словосочетания отражались в правой колонке. Причем отражались по степени «релевантности» (близости) к исходной фразе. Например:

На картинке мы видим в правой колонке смежные запросы по искомой фразе «семантическое ядро». Сначала идет запрос «ядро сайта», как наиболее релевантное сочетание по заданной нами фразе. И оно действительно очень близкое.
Но затем идут варианты «семантический сайт» и «Key Collector». Первый запрос получился как суррогат из запроса «семантическое ядро сайта» (об этом говорит число точного вхождения — за прошлый месяц в Яндексе такой запрос сделал всего 1 человек!). Второй — это название профессиональной программы для сбора СЯ.
В общем, правая колонка Вордстата не всегда информативна, но ее стоит все время просматривать в поиске похожих слов по теме нашей искомой фразы. Это позволит расширить сбор семантического ядра сайта, найти хорошие ключи для рекламной компании в Яндекс Директе.
Инструмент «По регионам»
Для определения региональной популярности любого поискового запроса в сервисе Yandex Wordstat есть инструмент «По регионам». Вот так выглядят элементы его интерфейса:

- Переключатель регионов (1). Можно выбрать все подряд, только регионы или только города.
- Переключатель для варианта отображения информации (2). Можно просмотреть популярность или в виде таблицы с данными (список), или в виде интерактивной карты.
- Общее число показов по заданному запросу (3) . Кстати, в примере один и тот же запрос — «внутренняя перелинковка». И теперь опять другая цифра — 1663. Думаю, Вы знаете, почему.
- Число показов в месяц (4) . Количество показов заданного запроса для каждого региона (города).
- Региональная популярность (5). Это доля, которую занимает регион (город) в показах по искомой фразе, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.
По интерпретации последнего значения сервис Вордстат дает такую рекомендацию:
- = 100% — запрос в данном регионе ничем не выделен;
- < 100% — интерес региона по запросу пониженный;
- > 100% — интерес региона по запросу повышенный.
Данный инструмент чаще всего полезен в двух случаях — для определения семантического ядра коммерческого сайта и для подбора ключей рекламной кампании. Для информационных сайтов и блогов региональная популярность редко используется.
Инструмент «История запросов»
Статистика Вордстат дает еще одну полезную информацию — . Благодаря этим данным пользователь может увидеть динамику популярности фразы в течение года. Более детально об этом Вы узнаете из следующего поста «Как использовать сезонные запросы». А пока посмотрим, из каких элементов состоит интерфейс этого инструмента:

- Переключатель единицы измерения (1) . Он позволяет увидеть динамику популярности по месяцам и по неделям.
- График изменения популярности запроса (2) . Два графика изменения абсолютных и относительных значений.
- Шкала измерения (3) . В зависимости от выбранной единицы измерения изменяются деления шкалы (появляются при наведении на графики).
- Абсолютное значение (4) . Число показов поискового запроса за указанный промежуток по шкале.
- Относительное значение (5) . Показатель дает информацию о том, насколько прогноз (абсолютное значение) отличается от реальности.
Операторы сервиса «Подбор Слов»
Для того, чтобы работа в сервисе статистики Яндекса не затягивалась долго и была более точной, существует ряд вспомогательных операторов. Все они используются только в инструменте «По запросам» и вносятся в поле вода поисковой фразы. Рассмотрим каждый оператор по отдельности.
Минус (-)
Оператор предназначен для исключения из списка запросов ненужных слов (так называемые «минус-слова»). Используется в разных случаях, чаще всего для поиска запросов СЯ для коммерческих проектов. Например, сравните левые колонки Вордстата по запросу «внутренняя перелинковка». В первом случае обычная фраза, во втором — исключены запросы со словом «страница»:

Замечу, что минусовали мы в примере слово «страница». В итоге Вордстат исключил все варианты слова с любым падежом.
Плюс (+)
С помощью оператора «плюс» мы принудительно ставим указание сервису на проверку запроса с предлогами и союзами (без этого оператора они исключаются). Вот пример работы этого оператора:

Как видим из примера, в первом случае число запросов с фразой «как готовить омлет из яиц» было самым большим — 712. Это тоже самое, если бы мы набирали запрос в Вордстате — «готовить омлет яиц». Во втором случае число запросов стало меньше, так как мы захотели увидеть их с учетом предлога «из». В третьем их стало еще меньше — появилось слово «как».
В Вордстате по умолчанию при вводе запроса без плюсов в левой колонке дается значение именно с плюсами:

Оператор «плюс» важен тогда, когда нам необходимо знать популярность запросов именно со всеми предлогами и союзами. Такое нередко бывает при подборе ключевых слов, например, для интернет-магазинов.
Или и группировка | ()
Оператор «или» позволяет собрать поисковые запросы, слова которых могут иметь разное написание, но одинаковое значение. Например, нам нужны все запросы по созданию блюда «омлет». Для этого мы возьмем сборку трех одинаковых по смыслу словосочетания:

В итоге в левой колонке мы получим все запросы по этим трем фразам.
Ту же самую задачу можно решить, если использовать оператор «группировка». В этом случае нам не нужно будет писать три раза слово «омлет»:

Итак, оператор «или» позволяет нам указать в искомой фразе варианты каких-то слов. Если слов с вариантами несколько, используется «группировка». В итоге получается максимально возможная подборка запросов. Например:

Кавычки («»), восклицательный знак (!)
Используя данный оператор, при подсчете запросов для левой колонки, Вордстат будет считать показы только этой фразы. При подсчете будут также учитываться различные словоформы фразы, а также разный порядок слов. Например, вот какую нам статистику предложит Вордстат по запросу «весенняя капель»:

Оператор «восклицательный знак» учитывает показы по форме слова, которую мы указали, без каких-то изменений (не учитываются различные словоформы):

Небольшое замечание — восклицательный знак ставиться непосредственно перед словом, пробел между оператором «!» и словом не ставится.
Точная частотность запроса
В поисковом продвижении используется совместная связка этих операторов. Число показов искомой фразы с этими операторами называется «точной частотой (частотностью) запроса»:

При таком построении искомой фразы с помощью этих операторов мы можем подсчитать запросы, которые не могут менять как сам запрос, так и его словоформы (например, окончания). Это позволит нам с учетом кликабельности сниппета дать примерное число показов продвигаемой страницы по этому запросу в Яндексе (в зависимости от занимаемого места в топе).
Именно поэтому при составлении семантического ядра мы обращаем внимание на точную частотность запроса.
Благодаря специальным операторам, мы можем в Вордстате узнать нужные нам запросы и число их показов практически по любым нашим требованиям. Например, нам нужны запросы по рецептуре блинов с такими ограничениями:
- в запросах должны быть слова «рецепт» и «приготовить»;
- берем разные варианты по типу блюда (блины, блинчики);
- в запросах нет ингредиента «молоко»;
- хотим запросы, чтобы было там точное слово «кефир».
В итоге у нас получается запрос со следующими операторами и соответствующим списком найденных фраз:

Схема работы в Вордстате
Вся структура сервиса четко выполняет одну функцию — поиск фраз. Вот схема получения и обработки поисковых запросов в Яндекс Вордстате:

Как видим, для поиска фраз используются различные инструменты сервиса и специальные операторы. Также есть дополнительный вариант получения поисковых словосочетаний — это правая колонка. Она бывает не у всех фраз и как правило, в нее входят те запросы, которые набирались при поиске основной фразы.
Для различных тематик сайтов из этой схемы могут выпадать инструменты «История запросов» и «По Регионам». Также есть некоторые отличия использования сервиса Вордстат для информационных и коммерческих ресурсов.
На этом небольшое руководство по использованию Яндекс Вордстата закончено. В следующих постах я расскажу, как работать с сезонными запросами и как можно проще и удобней работать в статистике с помощью специальных плагинов.
С уважением, Ваш Максим Довженко